Apache Kafka in een notendop
Apache Kafka is een erg flexibel streamingplatform. Het platform richt zich op schaalbare, real-time datapijplijnen die supersnel en langdurig zijn. Maar hoe werkt Apache Kafka precies en waar gebruik je het voor?
Hoe werkt Apache Kafka?
Voor een geruime tijd werden applicaties gebouwd met een database, waar dan bepaalde items in opgeslagen worden, zoals een bestelling, een persoon, een auto, noem maar op. De database sloeg deze items op met een bepaalde status.

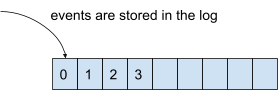
Kafka doet het op een andere manier: deze slaat namelijk geen 'items' op, maar 'events'. Een event heeft ook een bepaalde status, maar dan als iets dat gebeurd is in een bepaalde tijdspanne. Het is echter wat omslachtig om events in een database op te slaan. Daarom gebruikt Kafka een log (logboek): een geordende lijst van events die altijd blijft bestaan.
Ontkoppeling
Wanneer je een systeem hebt met verschillende bron- en doelsystemen, wil je al deze systemen met elkaar gaan integreren. Die integraties zijn een heel werk, omdat ze vaak hun eigen protocollen, dataformaten en verschillende structuren hebben.
Binnen een systeem van 5 bron- en 5 doelsystemen, zul je dus waarschijnlijk maar liefst 25 integraties moeten schrijven. Je snapt dat dit al snel erg ingewikkeld en tijdrovend kan worden.
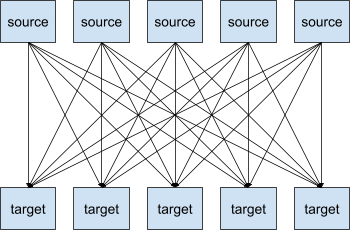
Maar dit is waar Kafka kan schitteren. Met dit platform ziet bovenstaande integratieschema er plots helemaal anders uit:
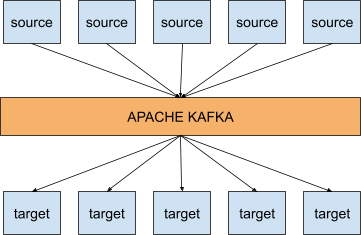
Wat betekent dat nu concreet? Wel, het betekent dat Kafka helpt om je verschillende datastromen te ontkoppelen. De bronsystemen hoeven enkel hun events naar Kafka toe te publiceren en doelsystemen hoeven enkel events vanuit Kafka te onttrekken. Bovendien laat Kafka zich erg gemakkelijk schalen, kan het gemakkelijk verdeeld worden, kent het platform een hoge mate van performantie en is de architectuur erg flexibel.
Topics and partities
Een topic is een specifieke datastroom en is gekend door een specifieke naam. Topics bestaan uit partities. Elke boodschap in een partitie is geordend en krijgt een incrementele ID, wat we 'offset' noemen. Een offset heeft enkel betekenis binnen een specifieke partitie.
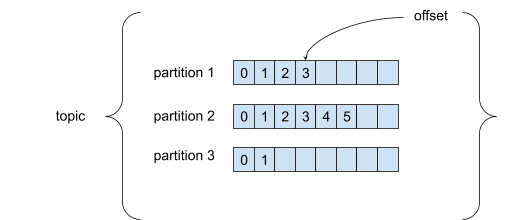
Binnen een partitie is de volgorde van de boodschappen gegarandeerd. Wanneer je een boodschap verstuurt naar een topic, wordt deze willekeurig aan een partitie toegewezen. Als je dus de volgorde van bepaalde boodschappen wil behouden, moet je aan de boodschappen een sleutel meegeven. Een boodschap met een sleutel wordt namelijk altijd toegewezen aan dezelfde partitie.
Bovendien zijn boodschappen onveranderlijk. Wil je toch een boodschap veranderen, dan zul je een extra 'update-boodschap' moeten versturen.
Brokers
Een Kafka cluster bestaat uit verschillende agenten (brokers). Elke broker heeft een ID en elke broker bevat bepaalde partities. Wanneer je verbindt met een broker binnen de Kafka cluster, ben je automatisch verbonden met de volledige cluster.
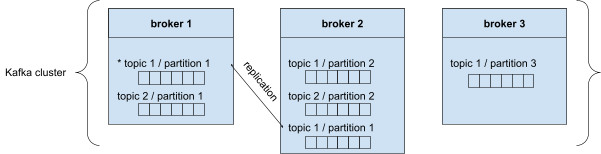
Zoals je kan zien in bovenstaande illustratie, wordt topic 1/partitie 1 herhaald in broker 2. Slechts één broker kan de leider zijn voor een topic of partitie. In dit voorbeeld is broker 1 de leider en zal broker 2 automatisch de herhaalde topics en partities synchroniseren. We noemen dit een ‘in sync replica’ (ISR).
Producers
Een producent (producer) verstuurt boodschappen naar de Kafka cluster zodat ze in een specifiek topic kunnen worden opgeslagen. Daartoe moet de producer de naam van het topic en één broker kennen. We stelden hierboven al dat je automatisch verbonden bent met de hele Kafka cluster wanneer je met een broker verbonden bent. Kafka zorgt zelf voor de juiste routering naar de specifieke broker.
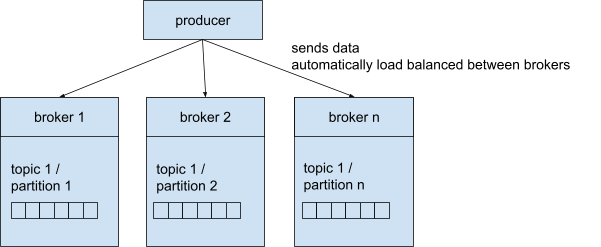
Een producer kan ingesteld worden om een erkenning (acknowledgement / ACK) te krijgen van het schrijven van data:
ACK=0: producer zal niet wachten op acknowledgement
ACK=1: producer zal wachten op acknowledgement van de leider-broker
ACK=ALL: producer zal wachten op acknowledgement van de leider-broker en van de replicabroker
Een hogere ACK is natuurlijk een veiliger proces en zorgt gegarandeerd voor geen dataverlies. Het nadeel hiervan is dat dit ook wat minder performant is.
Consumers
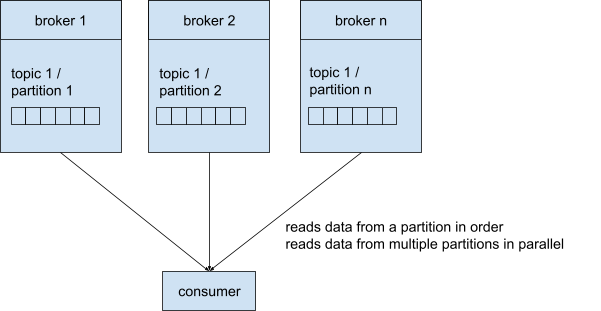
Een consument (consumer) leest de data van een bepaald topic. Daartoe moet de consumer de naam van het topic en één broker kennen. Net zoals de producers zorgt Kafka hier zelf voor de correcte routering naar de juiste broker.
Consumers lezen de boodschappen van een partitie in volgorde, rekening houdend met de offset. Indien consumers van meerdere partities lezen, worden deze in parallel afgehandeld.
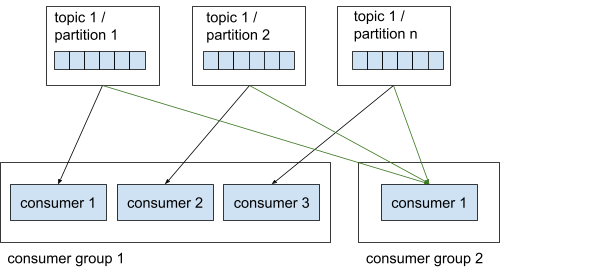
Consumer groups
Consumers worden georganiseerd in groepen, wat we in het Engels consumer groups noemen. Deze groepen zijn nuttig om parallellisme te verbeteren. Binnen een consumer group leest elke consumer van één exclusieve partitie. Dat betekent dat consumer 1 en 2 in consumer group 1 niet van dezelfde partitie kunnen lezen. Een consumer group kan ook niet meer consumer hebben dan partities om van te lezen, omdat sommige consumers dan geen partitie zullen hebben om van te lezen.
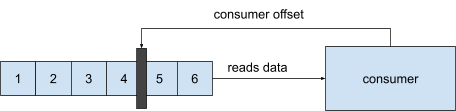
Consumer offset
Wanneer een consumer een boodschap leest van een partitie, past deze elke keer de offset toe. In het geval dat een consumer of het netwerk plat gaat, weet de consumer waar deze moet verdergaan zodra alles weer online staat.
Waarom we geen message queue gebruiken
Er zijn een paar veschillen tussen Kafka en een message queue. Enkele grote verschillen zijn dat wanneer een consumer in een message queue een boodschap ontvangt, deze verwijderd wordt van de queue. In Kafka gebeurt dit niet en worden de boodschappen/events dus niet verwijderd.
Dit laat toe dat er meerdere consumers per topic kunnen zijn, die dan dezelfde boodschappen kunnen lezen, maar verschillende logica hierop kunnen toepassen. Aangezien de boodschappen altijd blijven bestaan, kunnen deze ook opnieuw afgespeeld worden. Wanneer je daarentegen meerdere consumers hebt in een message queue, passen deze in het algemeen dezelfde logica toe op de boodschappen en zijn ze dus enkel nuttig om de load te verdelen.
Use cases voor Apache Kafka
Er zijn heel wat interessante use cases voor Kafka. Hier staan een paar voorbeelden op een rijtje!
Telemetrie van pakketbezorging
Wanneer je iets bestelt op een webshop, krijg je meestal een melding van de koerierdienst met daarin een link om je pakketje te volgen. In sommige gevallen kun je zelfs de chauffeur in real-time volgen op een kaart. Dit kan bijvoorbeeld met Kafka: de bestelwagen van de koerier heeft een GPS die regelmatig de huidige coördinaten naar een Kafka cluster verstuurt. De kaart waarop je de positie van de chauffeur bekijkt, luistert naar deze events en toont je vervolgens de locatie van de chauffeur op de kaart in real-time.
Tracking van activiteit op een website
Kafka kan ook gebruikt worden voor het tracken en opslaan van activiteit op een website. Events zoals paginaweergaven, zoekopdrachten van gebruikers enz. worden opgeslagen in Kafka topics. Deze data wordt dan gebruikt in bijvoorbeeld real-time monitoring, real-time verwerking of de data in een data lake inladen voor latere offline verwerking en rapportage.
Monitoren van de status van een applicatie
Servers kunnen gemonitord worden en alarmen doen afgaan wanneer er zich een systeemfout voordoet. Informatie van de servers kan gecombineerd worden met server syslogs en dan naar een Kafka cluster gestuurd worden. Door Kafka kunnen deze topics dan alarmbellen doen afgaan gebaseerd op bepaalde grenswaarden, completere informatie bevatten voor gemakkelijkere probleemoplossing voor er zich echte catastrofes voordoen.
Conclusie
In deze blogpost hebben we kort uitgelegd hoe Apache Kafka werkt en waar je dit krachtige platform voor kan gebruiken. Hopelijk heb je wat bijgeleerd. Laat het ons zeker weten als je vragen hebt. Bedankt voor het lezen!