

Hoe auto-discovery van Kubernetes endpoints services opzetten in Prometheus
Het is vanzelfsprekend dat je monitoring nodig hebt wanneer applicaties in Kubernetes (K8s) gebruikt. Naarmate K8s groter en professioneler wordt en jaar na jaar meer wordt toegepast (en dat zal zo blijven), is het niet meer dan logisch dat veel bedrijven professionele online monitoring- en waarschuwingsoplossingen bouwen. Anderen hebben Helm grafieken ontwikkeld die snel en eenvoudig een K8s namespace installeren met kube-state-metrics, Prometheus, Grafana met dashboards en Alert manager - volledig klaar voor gebruik.
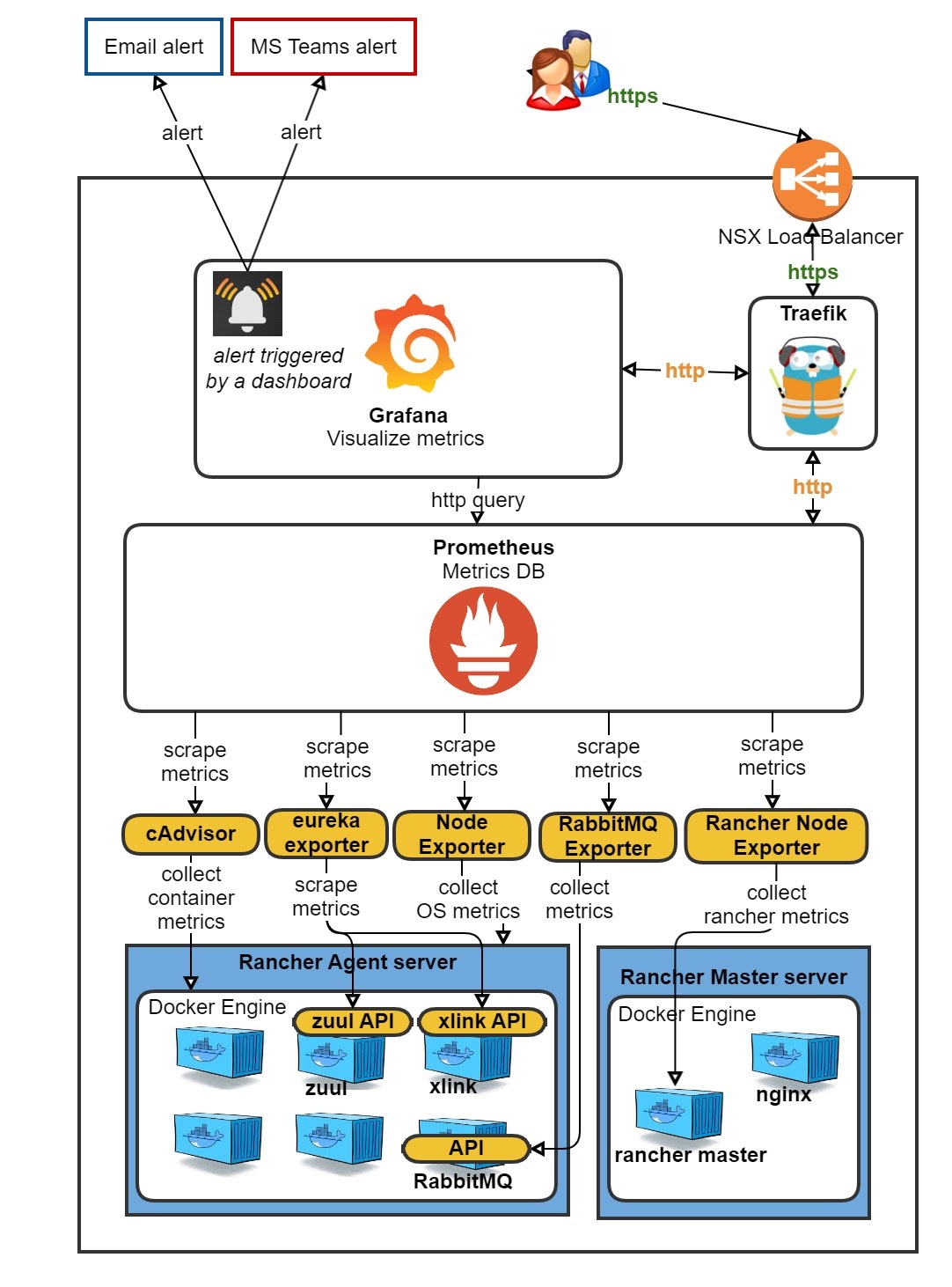
Het probleem hierbij is dat het allemaal nogal 'standaard' is. Als je al een volledig
aangepaste Prometheus/Grafana setup hebt in Rancher 1, zoals wij, is het zonde om dat zomaar weg te gooien. De reis van een Rancher 1 'cattle' Prometheus/Grafana naar Rancher 2 K8s verliep erg vlot en was vrij eenvoudig.
Met Prometheus zou je echter historisch gezien het bestand prometheus.yaml file moeten bewerken zodra je een nieuwe applicatie wil scrapen, tenzij je al je eigen aangepaste discovery tool als een scrape hebt toegevoegd.
Onvolledige data herstellen met auto-discovery
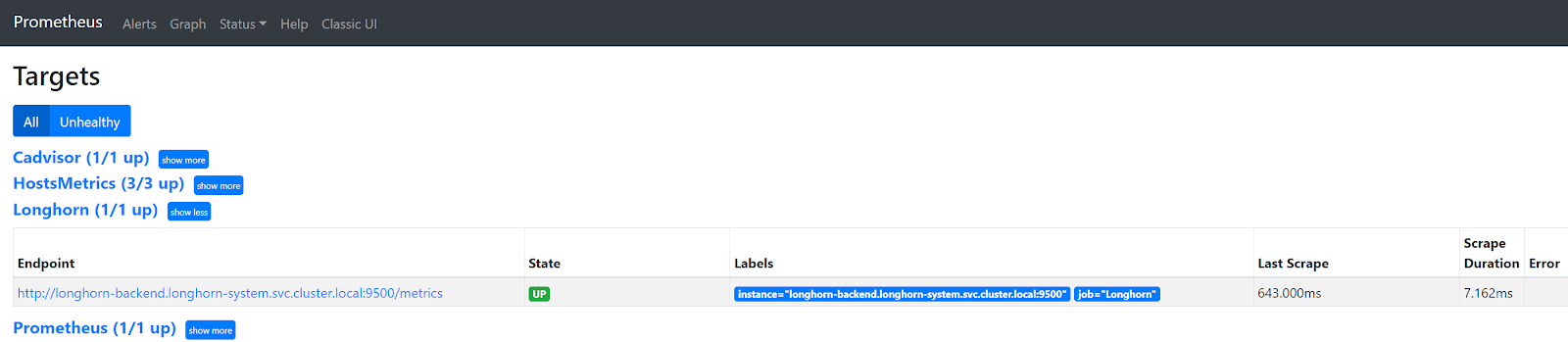
Een probleem dat ik ben tegengekomen bij het rechtstreeks scrapen van een Longhorn en Spring Boot (of een andere) Service in K8s, is dat slechts één van de vele backend pods achter die Service wordt gescrapet. Dus eindig je met onvolledige gegevens in Prometheus en als gevolg daarvan met onvolledige gegevens in je dashboards in Grafana. In Prometheus zie je dat slechts één van de drie bestaande Longhorn endpoints worden gescrapet.
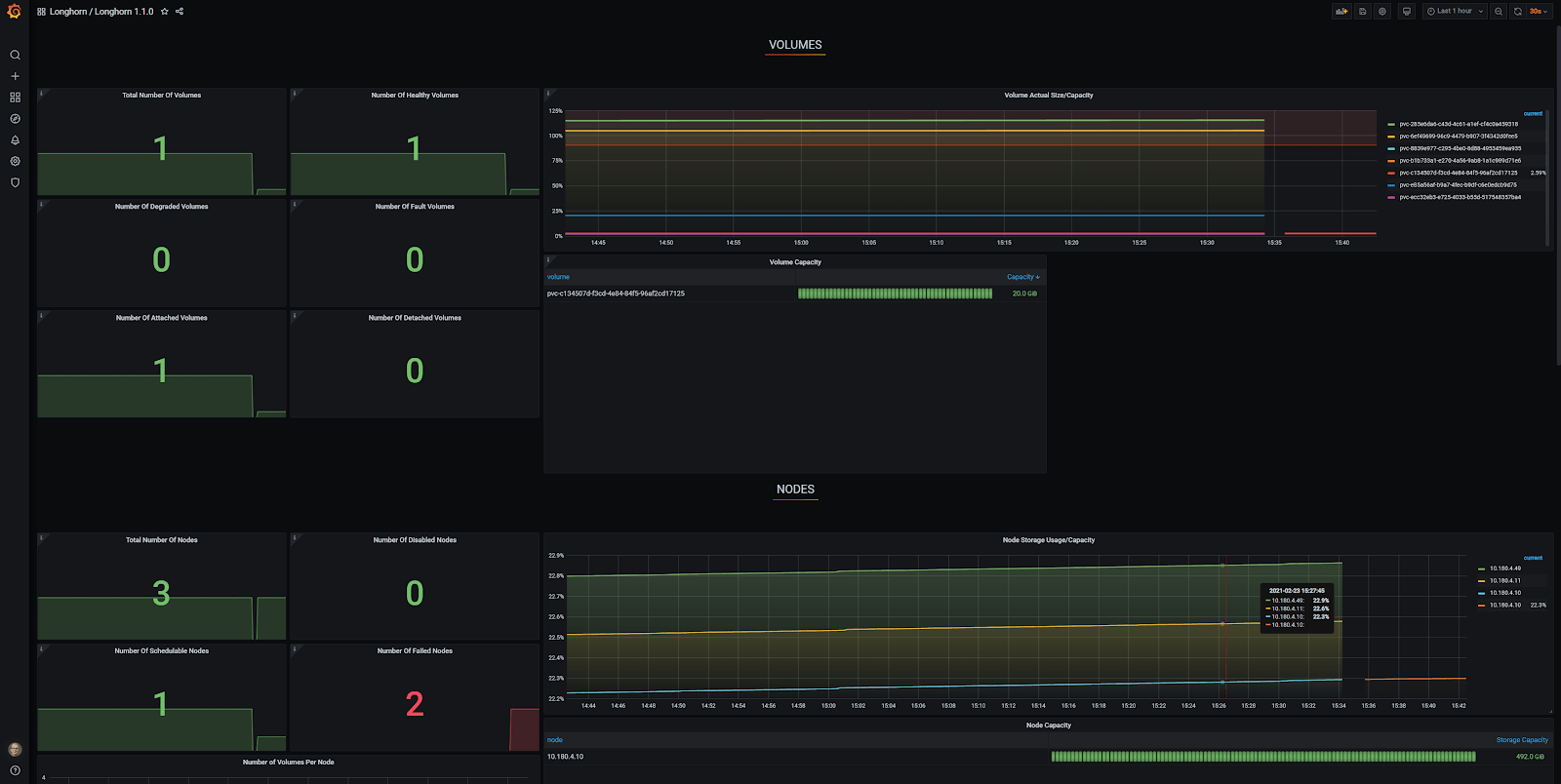
In Grafana zie je dat er maar één node is goedgekeurd en de andere twee worden gerapporteerd als 'Failed Nodes'. Bovendien wordt er maar één van de zeven delen gerapporteerd als 'Total Number of Volumes'.
Dit is waar auto-discovery van Kubernetes endpoint services als redder in nood optreedt. Veel webpagina's beschrijven de verschillende aspecten van het scrapen, maar naar mijn mening zijn geen van allen volledig en in andere omschrijvingen stonden dan weer grote fouten.
In deze blogpost geef ik jou een minimale en simpele configuratie om jouw Prometheus configuratie met auto-discovery van de Kubernetes endpoint services weer op en top
te krijgen!
1. Voeg configMap additions voor Prometheus toe
Voeg dit toe aan het einde van prometheus.yaml in je Prometheus configMap. De jobname is 'kubernetes-service-endpoints', want dat leek me wel toepasselijk
# Scrape config for service endpoints.
#
# The relabeling allows the actual service scrape endpoint to be configured
# via the following annotations:
#
# * `prometheus.io/scrape`: Only scrape services that have a value of `true`
# * `prometheus.io/scheme`: If the metrics endpoint is secured then you will need
# to set this to `https` & most likely set the `tls_config` of the scrape config.
# * `prometheus.io/path`: If the metrics path is not `/metrics` override this.
# * `prometheus.io/port`: If the metrics are exposed on a different port to the
# service then set this appropriately.
- job_name: 'kubernetes-service-endpoints'
scrape_interval: 5s
scrape_timeout: 2s
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: (.+)(?::\d+);(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name2. Configureer de Services
Zoals ik hierboven al eerder heb vermeld over prometheus.yaml, kun je de volgende
annotaties configureren. De annotatie prometheus.io/scrape: “true” is verplicht, indien je een bepaalde dienst wil scrapen. Alle andere annotaties zijn optioneel en worden hier uitgelegd:
- prometheus.io/scrape: Enkel scrape services die de waarde `true` hebben
- prometheus.io/scheme: Als de metrics enpoint beveiligd is, moet je dit instellen
op `https` en waarschijnlijk de `tls_config` van de scrape config instellen - prometheus.io/path: Als het metrics pad niet `/metrics` is, overschrijf deze dan
- prometheus.io/port: Als de metrics worden weergegeven op een andere poort dan de service, stel dit dan op de juiste manier in
Laten we eerst even kijken naar een voorbeeld van een Longhorn Service. (Longhorn is een goede gerepliceerde opslagoplossing!)
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/port: "9500"
prometheus.io/scrape: "true"
labels:
app: longhorn-manager
name: longhorn-backend
namespace: longhorn-system
spec:
ports:
- name: manager
port: 9500
protocol: TCP
targetPort: manager
selector:
app: longhorn-manager
sessionAffinity: ClientIP
sessionAffinityConfig:
clientIP:
timeoutSeconds: 10800
type: ClusterIPLaten we nu kijken naar een voorbeeld van een Spring Boot Application Service. Let op het niet-standaard scrape-path/actuator/prometheus.
apiVersion: v1
kind: Service
metadata:
name: springbootapp
namespace: spring
labels:
app: gateway
annotations:
prometheus.io/path: "/actuator/prometheus"
prometheus.io/port: "8080"
prometheus.io/scrape: "true"
spec:
ports:
- name: management
port: 8080
- name: http
port: 80
selector:
app: gateway
sessionAffinity: None
type: ClusterIP3. Configureren van Prometheus rollen
ClusterRole
Verander indien nodig eerst de namespace. Let op: misschien moet deze clusterRole een beetje strikter zijn dan het nu het geval is.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus
name: prometheus
namespace: prometheus
rules:
- apiGroups:
- apiextensions.k8s.io
resources:
- customresourcedefinitions
verbs:
- create
- apiGroups:
- apiextensions.k8s.io
resourceNames:
- alertmanagers.monitoring.coreos.com
- podmonitors.monitoring.coreos.com
- prometheuses.monitoring.coreos.com
- prometheusrules.monitoring.coreos.com
- servicemonitors.monitoring.coreos.com
- thanosrulers.monitoring.coreos.com
resources:
- customresourcedefinitions
verbs:
- get
- update
- apiGroups:
- monitoring.coreos.com
resources:
- alertmanagers
- alertmanagers/finalizers
- prometheuses
- prometheuses/finalizers
- thanosrulers
- thanosrulers/finalizers
- servicemonitors
- podmonitors
- prometheusrules
verbs:
- '*'
- apiGroups:
- apps
resources:
- statefulsets
verbs:
- '*'
- apiGroups:
- ""
resources:
- configmaps
- secrets
verbs:
- '*'
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- services
- services/finalizers
- endpoints
verbs:
- "*"
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- namespaces
verbs:
- get
- list
- watch
- apiGroups:
- extensions
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]ClusterRoleBinding
Verander de namespace nogmaals indien nodig.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/name: prometheus
name: prometheus
namespace: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: default
namespace: prometheusServiceAccount
Nogmaals, verander de namespace indien nodig. DON'T: verander de naam niet, tenzij je
ook de ClusterRoleBinding subjects.name verandert.
apiVersion: v1
kind: ServiceAccount
metadata:
name: default
namespace: prometheusPas toe
Pas als eerste de ServiceAccount, ClusterRoleBinding, ClusterRole en Services toe aan jouw K8s cluster. Nadat de Prometheus configMap is geüpdatet, implementeer Prometheus opnieuw om er zeker van te zijn dat de nieuwe configMap geactiveerd/geladen is.
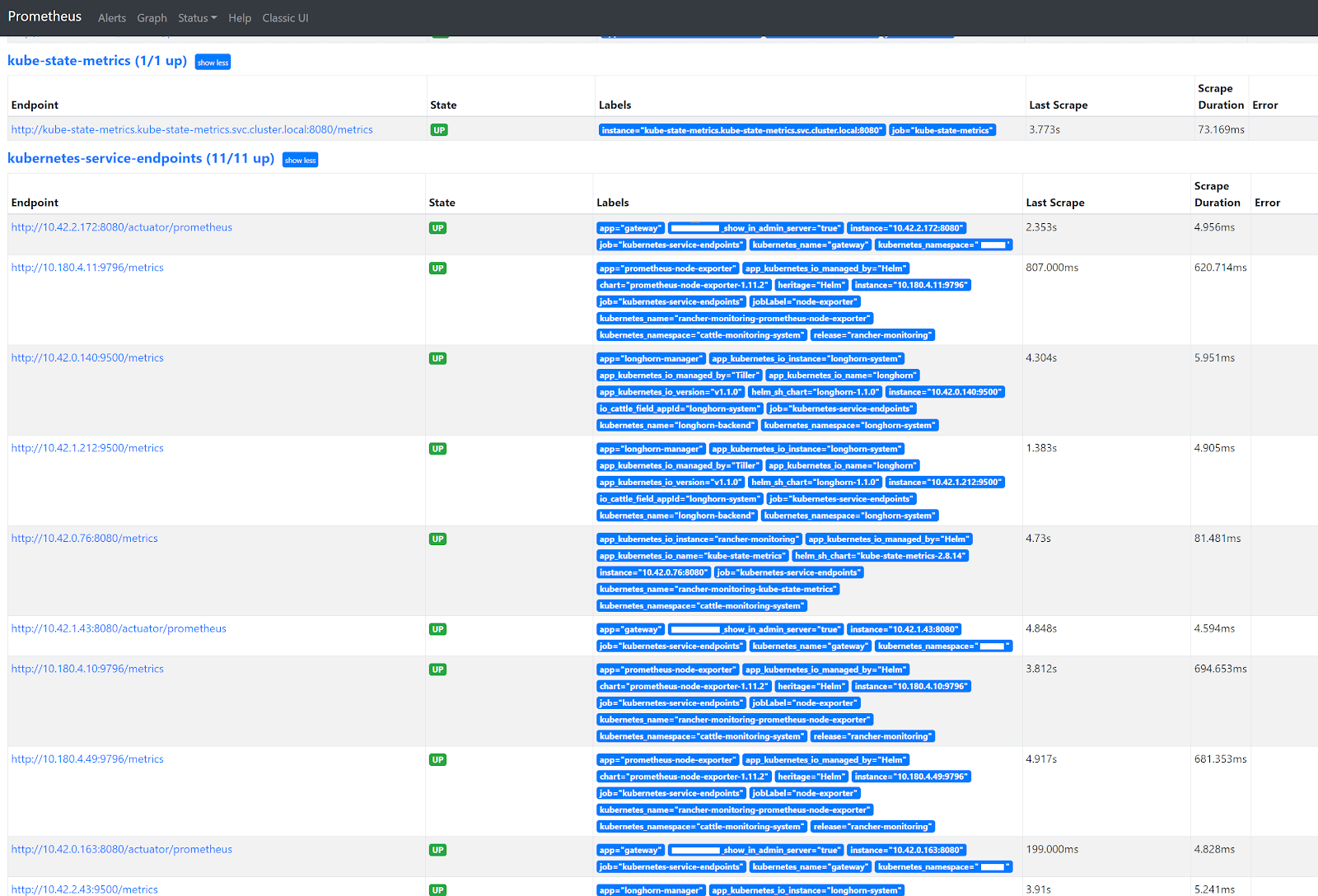
Resultaten in Prometheus
Ga naar de Prometheus GUI en navigeer naar Status -> Targets. Je zal zien dat alle pod endpoints 'op magische wijze' zullen verschijnen in de kubernetes-services-endpoints heading. Alle toekomstige prometheus.io gerelateerde annotatie aanpassingen in k8s Services zullen onmiddellijk in werking treden nadat je ze hebt aangebracht!
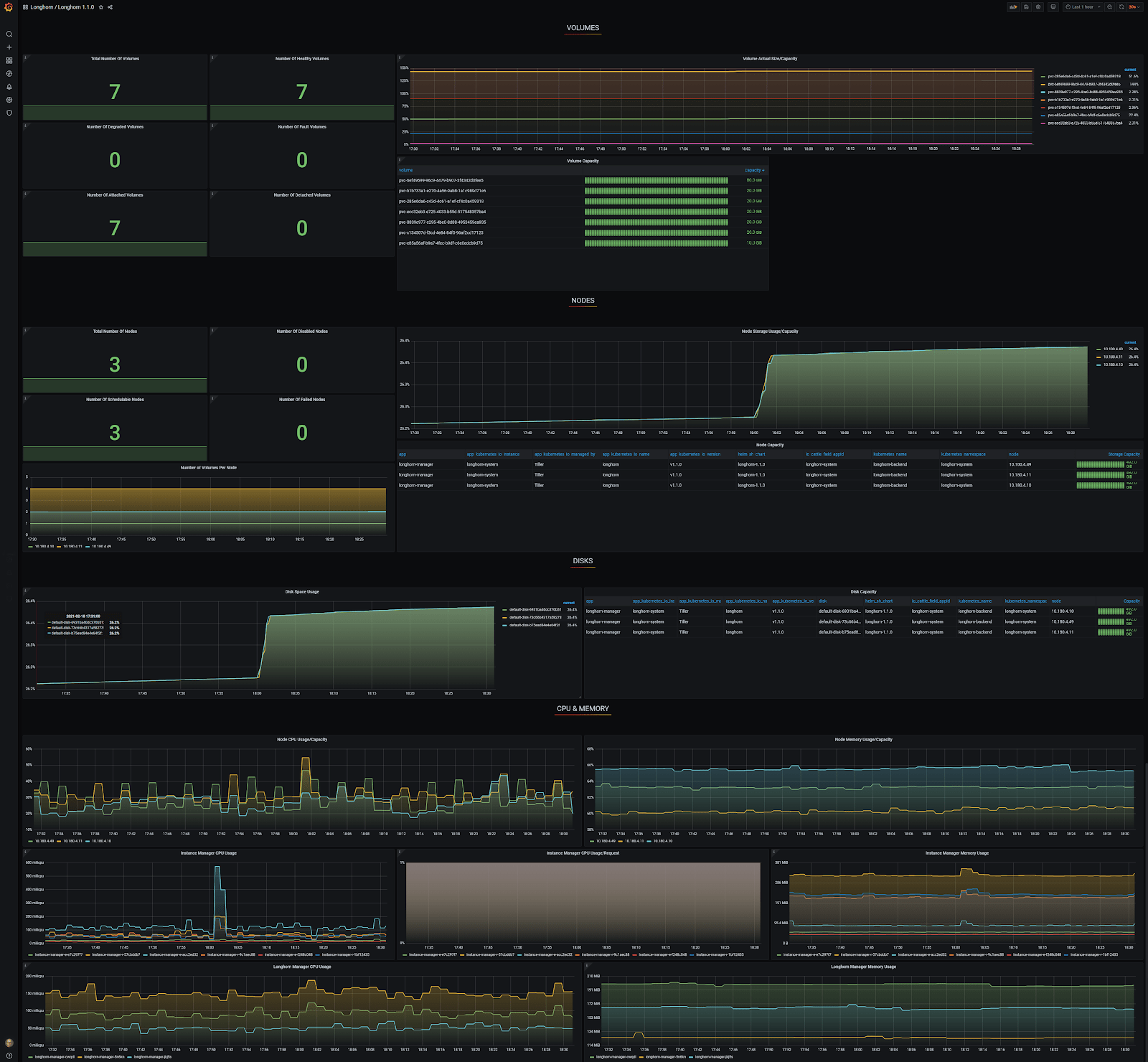
Grafana Longhorn dashboard
Ik heb een generiek Grafana Longhorn dashboard gebruikt, die je hier kan vinden. Dankzij auto-discovery geeft het Grafana Longhorn dashboard nu correct drie nodes en zeven volumes weer, wat klopt!
Conclusie
Na het doorlopen van alle stappen in deze blogpost, hoef je in principe nooit meer naar jouw Prometheus configuratie om te kijken. Dankzij auto-discovery van Kubernetes endpoint services is het toevoegen en verwijderen van Prometheus scrapes voor jouw applicaties nu bijna even gemakkelijk dan het ontgrendelen van jouw smartphone! ;-)
Ik hoop dat deze blogpost jou heeft geholpen! Aarzel zeker geen contact met ons op te nemen via hello@aca-it.be voor vragen.










