


De principes van data mesh toepassen op een IoT-data-architectuur
In een eerdere blogpost beschreven we een Internet of Things (IoT) case waarin de IoT-data onderdeel werden van een dataplatform van een onderneming. Hierdoor kan je de IoT-data combineren met andere datasets in je onderneming. De uitdaging is om je dataplatform zo te ontwerpen dat het meeschaalt met het aantal datasets, de nodige business agility biedt, voorkomt dat je met een onhoudbaar monolithisch data-architectuur eindigt en vermijdt dat slechts één team verantwoordelijk is en dus een knelpunt vormt om dingen voor elkaar te krijgen. In deze blogpost leggen we uit hoe data mesh je hierbij kan helpen. Aan de hand van een praktische use case laten we zien hoe je de principes van data mesh toepast op een IoT-dataplatform.
De evolutie naar data mesh
Om te begrijpen wat data mesh is en welke principes het nastreeft, bekijken we best eerst hoe de operationele wereld zich de afgelopen tien jaar heeft ontwikkeld.
Van monolitische architecturen naar microservices
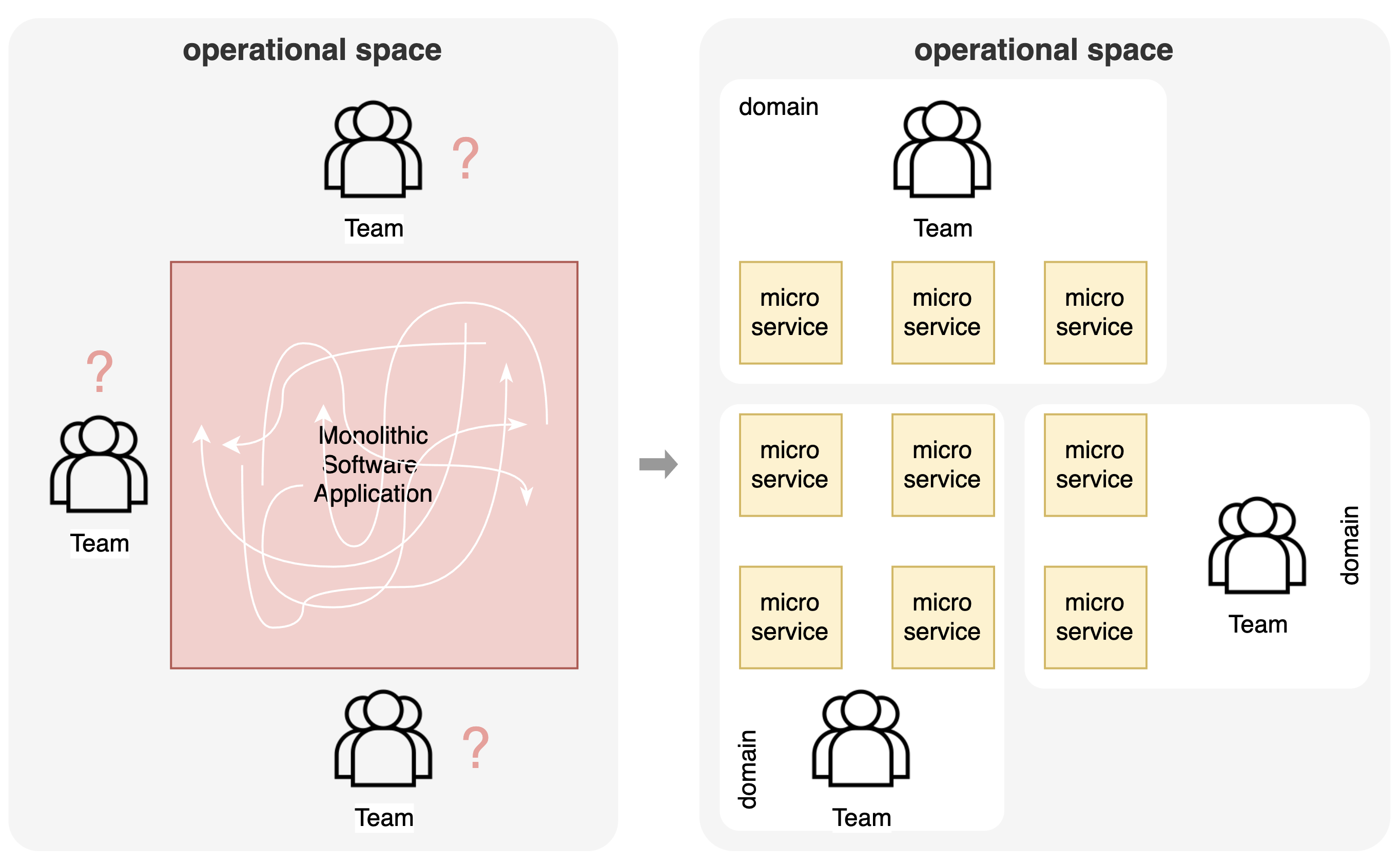
In het verleden werden software-applicaties vaak gebouwd als grote monolithische systemen met hun typische problemen:
- Een monolithische architectuur evolueert doorgaans naar één 'grote vergaarbak' die het moeilijk maakt om dingen te onderhouden, te wijzigen en om de nodige zakelijke wendbaarheid te bieden die een bedrijf nodig heeft.
- Tegelijkertijd biedt zo’n architectuur bij het opschalen naar meerdere teams binnen een bedrijf onvoldoende flexibiliteit.
- Het is bovendien onduidelijk welk deel van de software de verantwoordelijkheid is van welk team.
Als oplossing onderging de operationele wereld een evolutie naar een microservices-architectuur. Met behulp van domain-driven designtechnieken wordt een decompositie gemaakt op basis van business domeinen en in software services. De uitdaging is om de juiste granulariteit te vinden om de gewenste business agility mogelijk te maken. Zo wordt je architectuur ook schaalbaar naar meerdere teams. Elk team is verantwoordelijk voor een business domein, wat inhoudt dat voor elke microservice duidelijk slechts één team verantwoordelijk is.
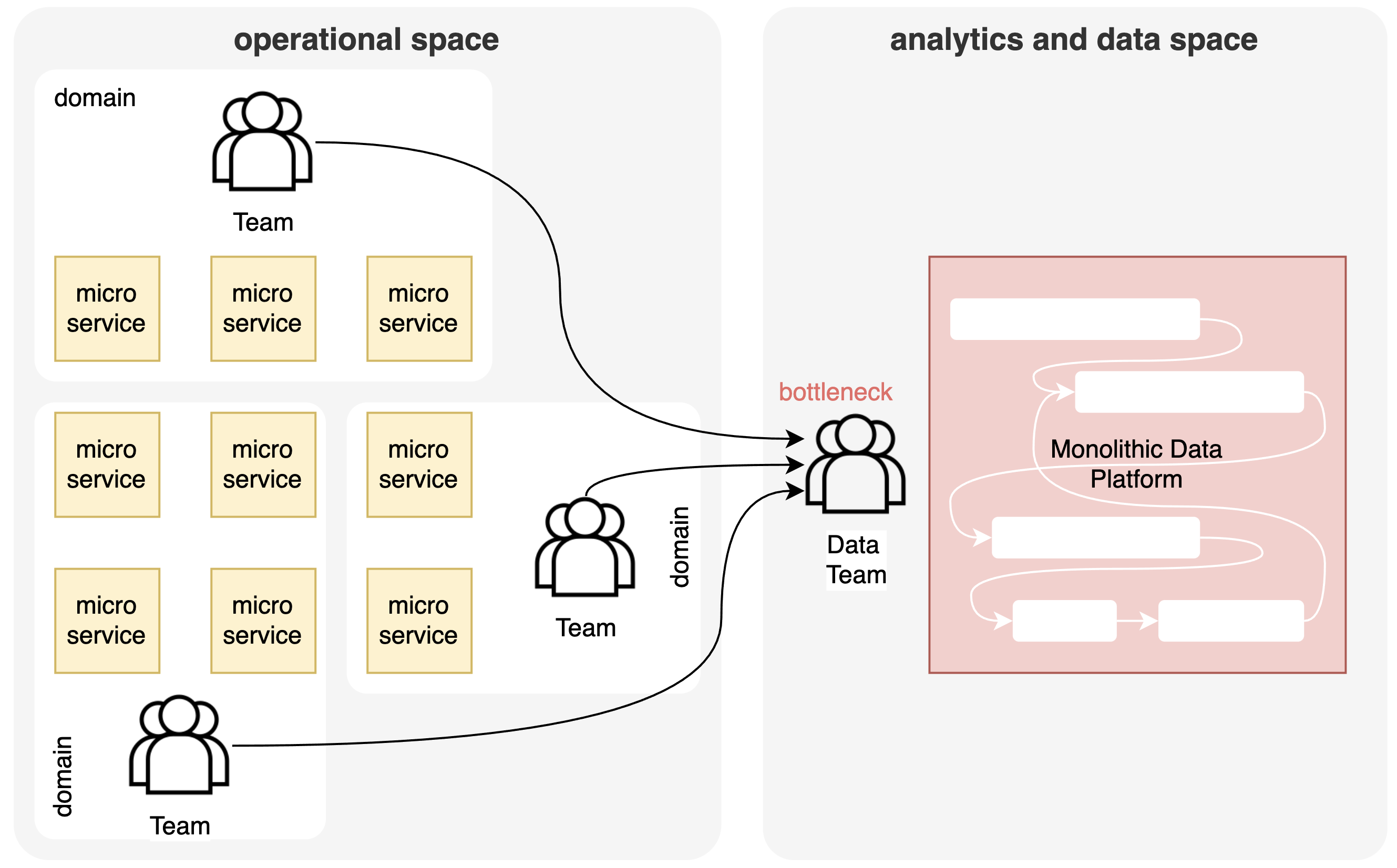
Als we de analytics- en datawereld naast de operationele wereld leggen, zien we ook hier een monolithische structuur in de vorm van data lakes en data warehouses die de verantwoordelijkheid zijn van een apart team van data-engineers. Dus zelfs als er een duidelijke decompositie is in de operationele wereld, is er nog steeds een monolithische structuur in de datawereld, wat resulteert in soortgelijke problemen.
Datapijplijnen hebben de neiging om in de loop van de tijd uit te groeien tot een onhoudbare puinhoop van aaneengeschakelde pijplijnen met lange uitvoeringstijden, hoge opslagvereisten, alles-of-niets-upgrades met downtime, enz. De verantwoordelijkheid om data te structureren en bruikbaar te maken, wordt toegewezen aan een centraal team van data-engineers, die een knelpunt worden wanneer de hoeveelheid datasets opschaalt en de frequentie van wijzigingen toeneemt. Dat is opnieuw een risico voor de business agility die een bedrijf nodig heeft.
Dataproducten voor meer structuur en ownership
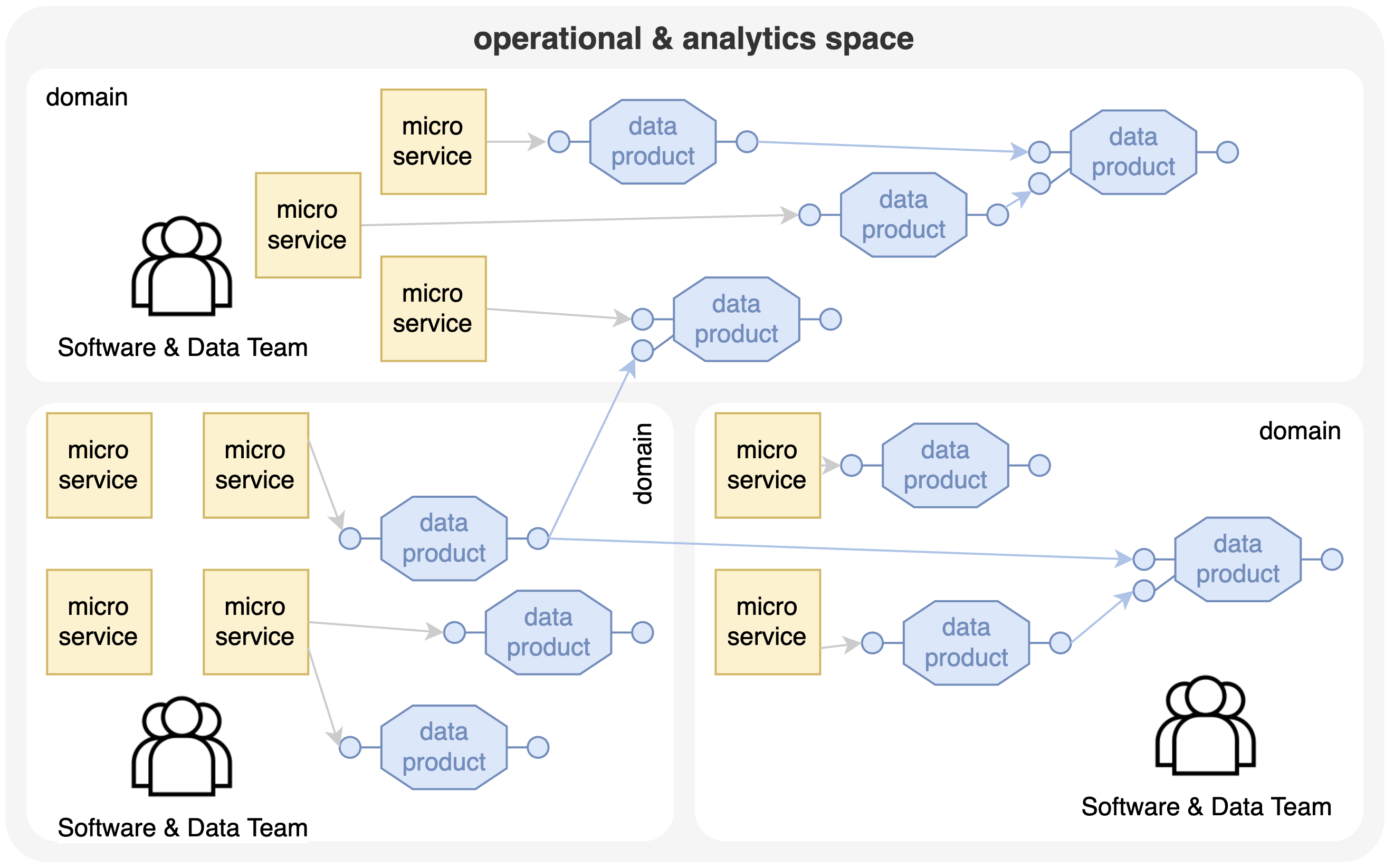
Ook voor de analytics- en datawereld hebben we dus nood aan een geschikte decompositie die aansluit bij de business domeinen waarvoor business agility gewenst is. Deze decompositie wordt een 'dataproduct' genoemd dat data van operationele diensten en andere dataproducten verwerkt en data produceert volgens een duidelijke API of datacontract. Deze dataproducten zijn, samen met microservices voor dat domein, de verantwoordelijkheid van de betreffende business domeinen.
Een multifunctioneel team van software-engineers en data-engineers is verantwoordelijk voor het bouwen, onderhouden en ontwikkelen van een domein. Zo ontstaat er een netwerk van onderling verbonden dataproducten, een 'data mesh' genaamd. Merk op dat er nog steeds verbindingen zijn tussen diensten en tussen dataproducten die kunnen resulteren in geavanceerde netwerken. Het grootste verschil is dat deze verbindingen duidelijke API's of contracten volgen die zijn gedefinieerd door componenten die het IT-landschap en het ownership ervan duidelijk structureren.
Vier Data mesh principes
Het concept van data mesh is geïntroduceerd door Zhamak Dehghani. Raadpleeg gerust haar onlangs gepubliceerde boek voor alle details.
Hieronder vind je de vier principes van data mesh. Deze principes vullen elkaar aan en pakken elk nieuwe uitdagingen aan die door andere kunnen ontstaan:
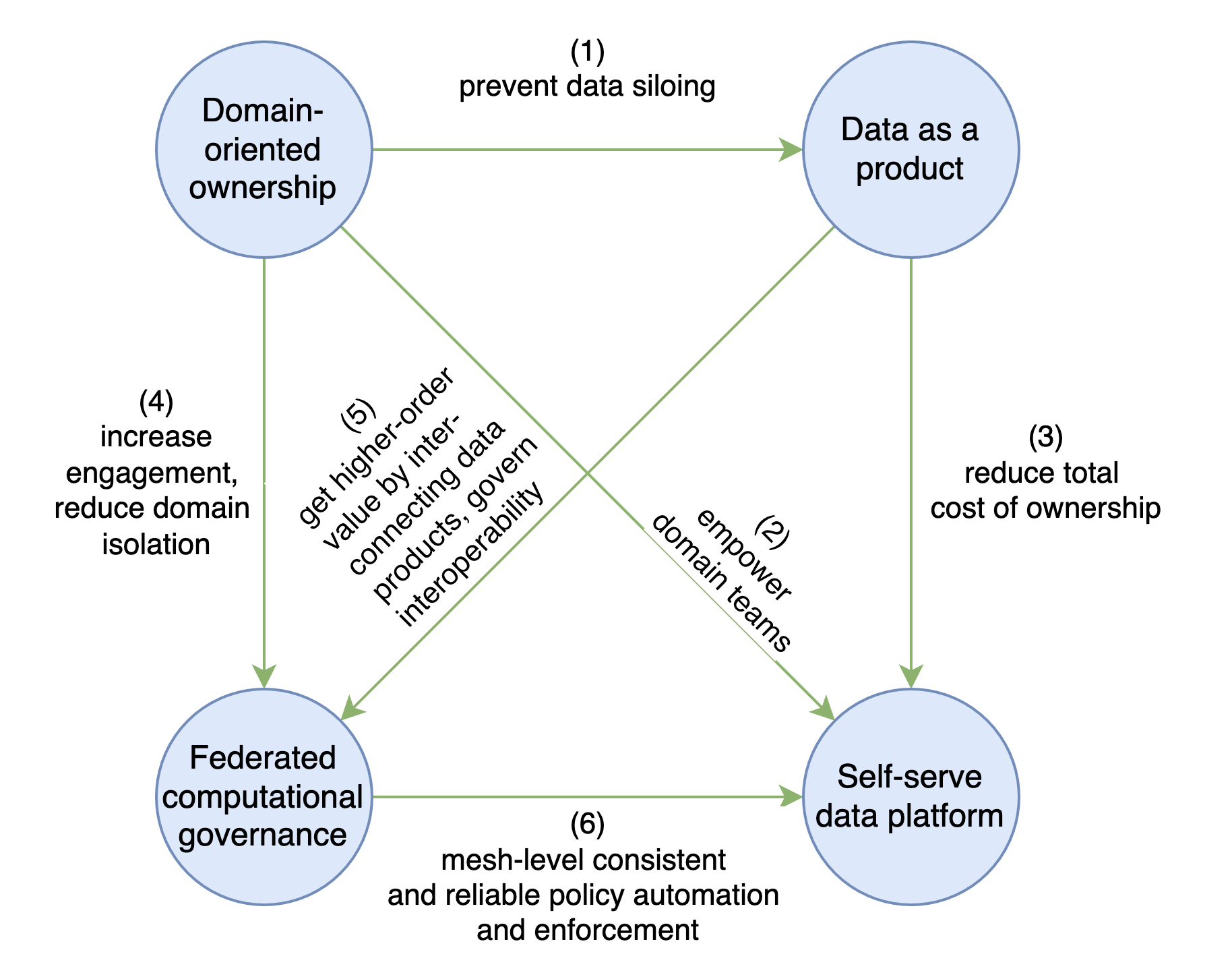
- Domain-oriented ownership: Decentraliseer het ownership van en de verantwoordelijkheid over analytische data naar business domeinen die zich het dichtst bij de data bevinden - ofwel de bron van de data ofwel de belangrijkste consumenten.
- Data as a product: Voorkom isolatie in domeinsilo's door het delen van data als product te stimuleren. Pas technieken uit product thinking en product ownership toe om een nieuwe autonome architecturale eenheid te ontwerpen met een datacontract-API die het gebruik door data-consumenten, data-analisten en data-scientists faciliteert.
- Self-serve data platform: Verlaag de total cost of ownership en elimineer de moeilijkheden die zich voordoen bij het delen, gebruiken en toegang krijgen tot data. Hoe? Met een gedeeld self-service platform dat de volledige levenscyclus van individuele dataproducten beheert (bouwen, implementeren en onderhouden), en mogelijkheden biedt op mesh-niveau om beschikbare dataproducten en verhoogde waarneembaarheid te ontdekken door middel van grafieken, datavergelijking en statistieken over de datakwaliteit en het gebruik van de mesh.
- Federated computational governance: Stap af van centraal beheer van data en verhoog de betrokkenheid van domeinen door gedecentraliseerde besluitvorming en verantwoording mogelijk te maken a.d.h.v. een team bestaande uit vertegenwoordigers uit de domeinen, experten van het platform en vakdeskundigen (bijv. Juridisch, compliance, beveiliging, enz.). Dit model combineert de autonomie en flexibiliteit van domeinen met de globale interoperabiliteit van de mesh. Door de onderlinge verbinding tussen dataproducten te vergemakkelijken, kan dit model de toegevoegde waarde van het totale systeem verhogen. De term 'computational' verwijst naar de automatisering van het governancebeleid voor elk dataproduct, dat kan worden afgedwongen via een betrouwbaar self-service platform.
Dataproduct als nieuw 'architecturaal quantum'
Volgens het boek 'Building Evolutionary Architectures' is een ‘architecturaal quantum’ een onafhankelijk deploybare component met een hoge functionele samenhang, die alle structurele elementen bevat die nodig zijn om goed te kunnen functioneren. Als zodanig is het 'dataproduct' in onze data mesh een nieuw ‘architecturaal quantum’. Het kan als volgt worden gevisualiseerd:



Een dataproduct omvat de volgende structurele elementen die nodig zijn om de data als product te leveren:
- 1 of meer inputpoorten die data opnemen van bronsystemen of andere dataproducten
- 1 of meer outputpoorten die de data in 1 of meer formaten en via 1 of meer protocollen beschikbaar stellen volgens een datacontract-API. Merk op dat 'API' niet beperkt is tot een typische REST API, het verwijst naar een overeengekomen technologie, formaat en protocol om data uit te wisselen. Dit kan een REST API zijn, maar ook een SQL-databaseverbinding, een S3-opslag, enz. Het mag echter nooit het interne model van een operationeel systeem zijn, maar een expliciet ontworpen extern model/tabel/schema dat als API dient.
- de dataopslag die intern nodig is of die nodig is om de data in een outputpoort beschikbaar te stellen
- de eigenlijke code die de transformatielogica van data uit inputpoorten naar data in outputpoorten toepast
- governancebeleid dat wordt afgedwongen binnen het dataproduct
- metadata die het dataproduct vindbaar en zelfdocumenterend maakt (discovery port)
- monitoring (i.e. metrics) en beheer van het dataproduct (control port)
Door dit dataproduct en zijn verschillende aspecten te gebruiken, kan een geschikte decompositie van een dataplatform worden uitgedacht en ontworpen.
IoT-data als eenvoudige use case
Laten we met een use case illustreren hoe een netwerk van dataproducten kan helpen als een bruikbare ontwerpmethodologie. De use case gaat over het gebruik van Internet of Things (IoT)-data samen met andere bedrijfsdata om waardevolle inzichten te bieden in het welzijn en de gezondheid van werknemers op de werkplek en kinderen op scholen. Voor een volledige beschrijving van de use case verwijzen we naar onze vorige blogpost getiteld 'Hoe we onze gezondheid verbeteren dankzij het IoT en digitale kanaries'.
In het kort zijn er 3 operationele systemen betrokken:
- een IoT-platform dat telemetriedata leest van de IoT-apparaten met behulp van Google Cloud IoT Core en Google Cloud Pub/Sub
- een Google-sheet waarin metadata over de IoT-apparaten worden vastgelegd (locatie, gebouw, verdieping, buiten CO2-niveau, ...)
- een Google-sheet waarin een logboek wordt bijgehouden van de ondernomen acties om de gezondheid van de werkomgeving te verbeteren, en daarmee de waarden die door de IoT-apparaten worden waargenomen, te verbeteren
Al deze systemen behoren tot het IoT-domein en zijn de verantwoordelijkheid van één team: het IoT-team.



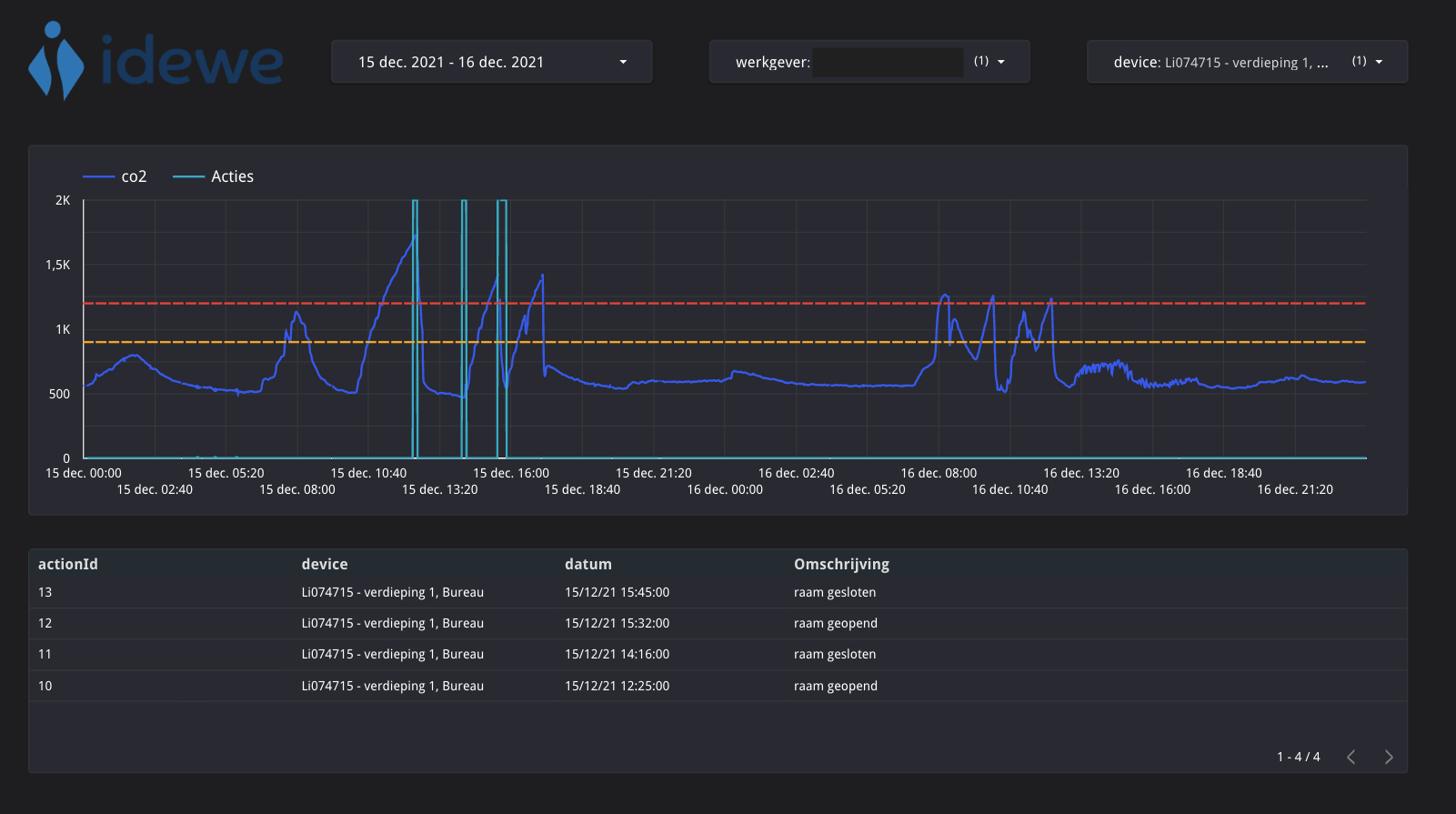
Voor analyse en rapportage wordt Google Data Studio gebruikt en beheerd door het data-analyseteam. Hieronder zie je een voorbeeld van een resulterend dashboard. In wat volgt laten we zien hoe een netwerk van dataproducten is ontstaan uit het ontwerp van het dataplatform. De resulterende data mesh brengt de data van de operationele systemen naar het gewenste dashboard.


Evolutie van de IoT data mesh
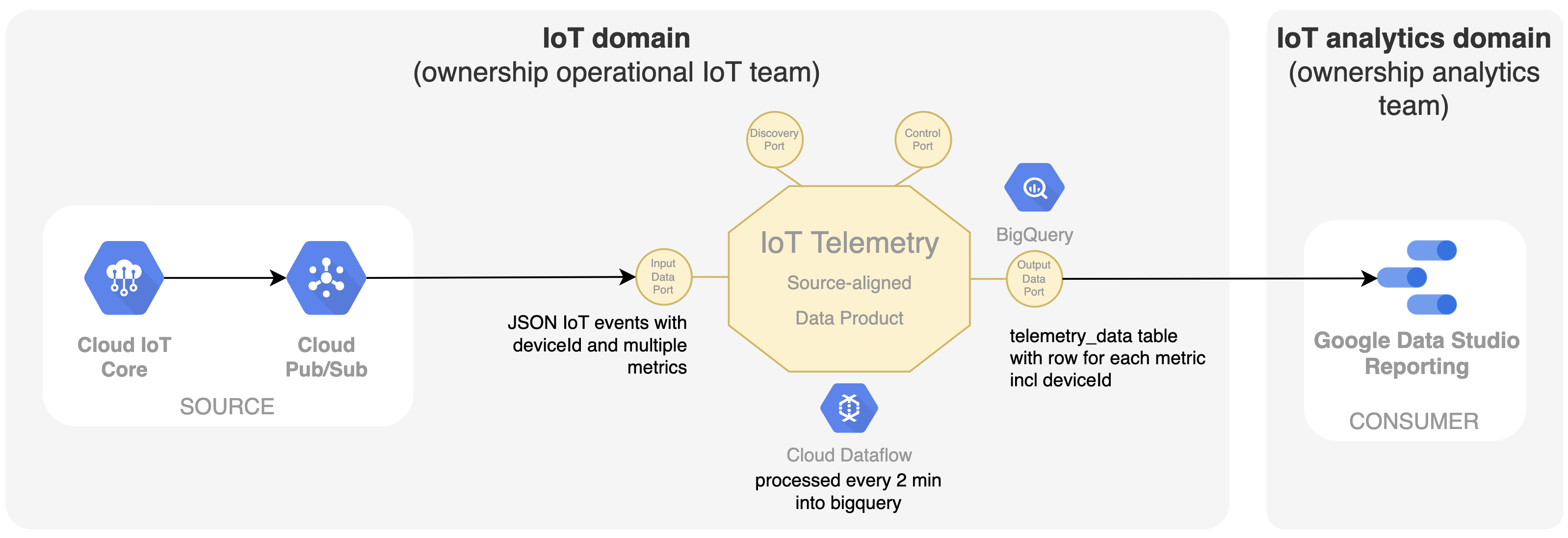
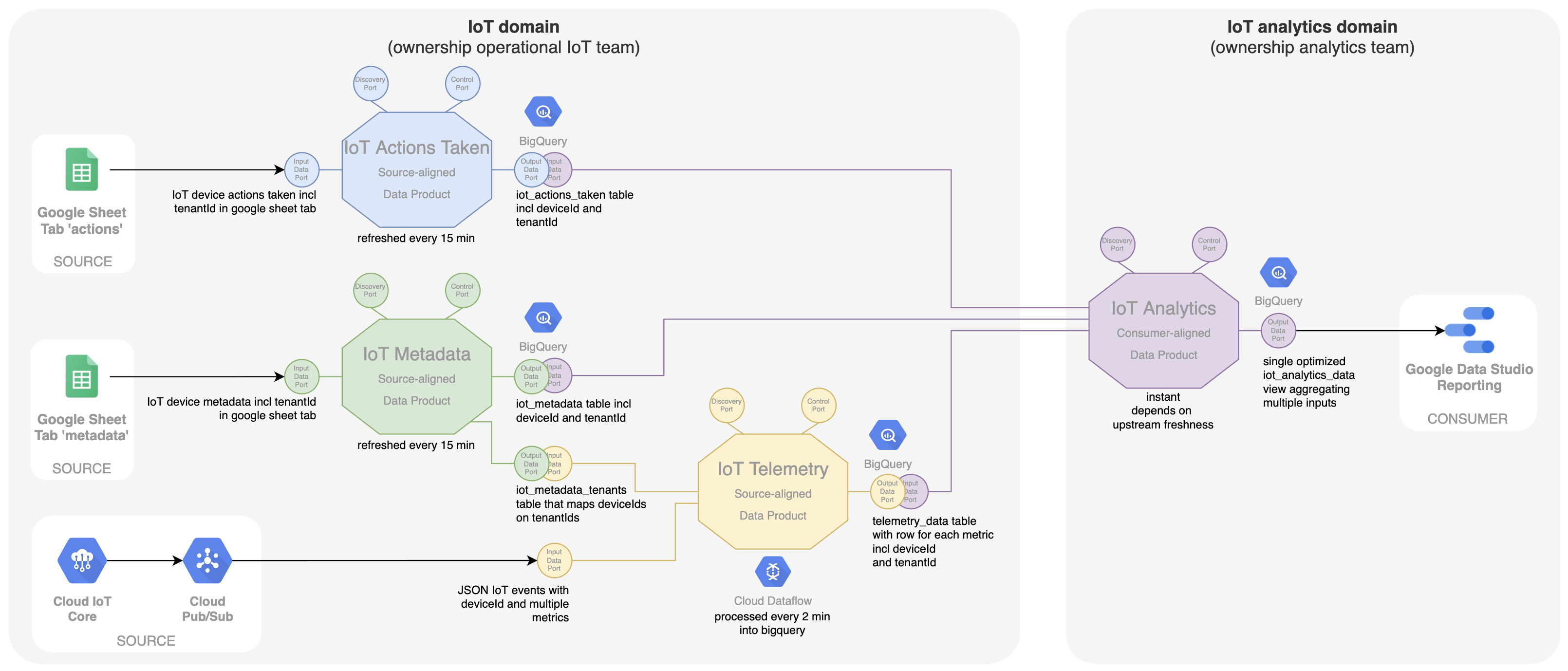
In IoT zijn de kerndata natuurlijk de telemetriedata die afkomstig zijn van de IoT-sensoren zelf. Het team dat eigenaar is van dit IoT-systeem is nu ook verantwoordelijk voor het delen van deze ‘time series data’ als een dataproduct op het data mesh platform. Ons eerste dataproduct 'IoT Telemetry' haalt de IoT-events met meerdere metingen uit Google Pub/Sub en transformeert ze met behulp van Google Dataflow in een SQL-querytabel in Google BigQuery, met één rij voor elke meting.
De ‘device-id’ is hier een belangrijke identifier. Bij gebruik van een meer centrale service zoals BigQuery voor een decentraal model zoals een data mesh, is het belangrijk om de grenzen binnen BigQuery duidelijk te kunnen definiëren. In dit geval wordt elk dataproduct een andere dataset binnen BigQuery, waardoor de teams specifieke toegangsrechten kunnen krijgen om alleen hun dataproduct te wijzigen en in te vullen. In data mesh wordt dit soort dataproduct een ‘source-aligned dataproduct’ genoemd, omdat het nauw verbonden is met het operationele bronsysteem en zijn data beschikbaar stelt aan de mesh. Voor het tonen van deze data in een grafiek kan het team dat verantwoordelijk is voor het dashboard in Google Data Studio direct uit de outputpoort van dit dataproduct lezen.
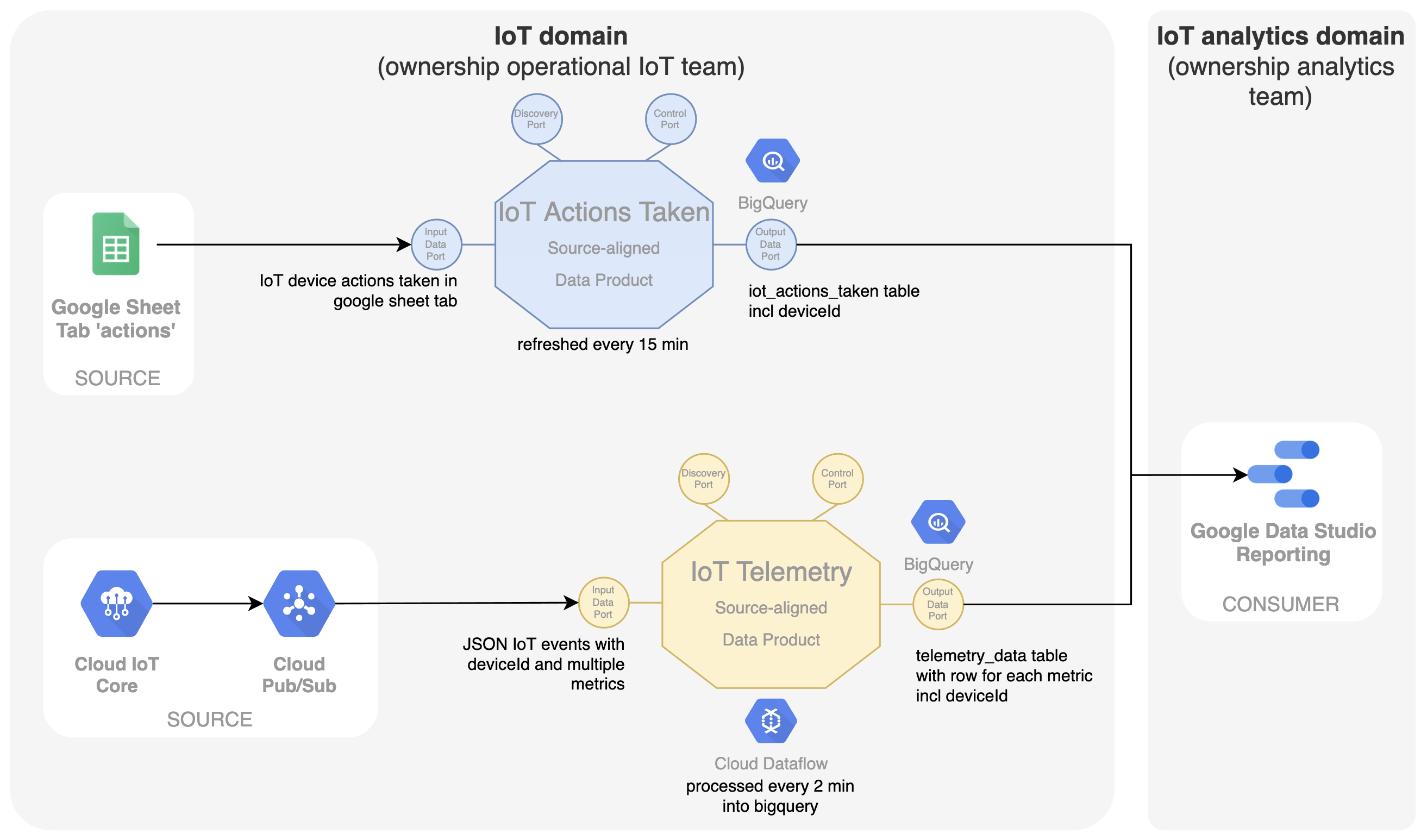
Naast de telemetriedata worden aanvullende data verzameld in eenvoudige Google-sheets. Een eerste sheet geeft de ondernomen acties weer als een soort logboek. In het dashboard worden deze acties uitgezet in de grafieken die de evolutie van telemetriedata tonen. Dit toont het mogelijke effect van de actie. Het IoT-team dat in het IoT-domein werkt, is weer eigenaar van deze operationele Google-sheet en is dus verantwoordelijk voor het openbaar maken van de data als dataproduct genaamd 'IoT Actions Taken'. Hier worden de data uit Google-sheets op Google Drive getransformeerd in een doorzoekbare SQL-tabel in BigQuery met behulp van een eenvoudige geplande zoekopdracht in een afzonderlijke tabel binnen de dataset van dit dataproduct.
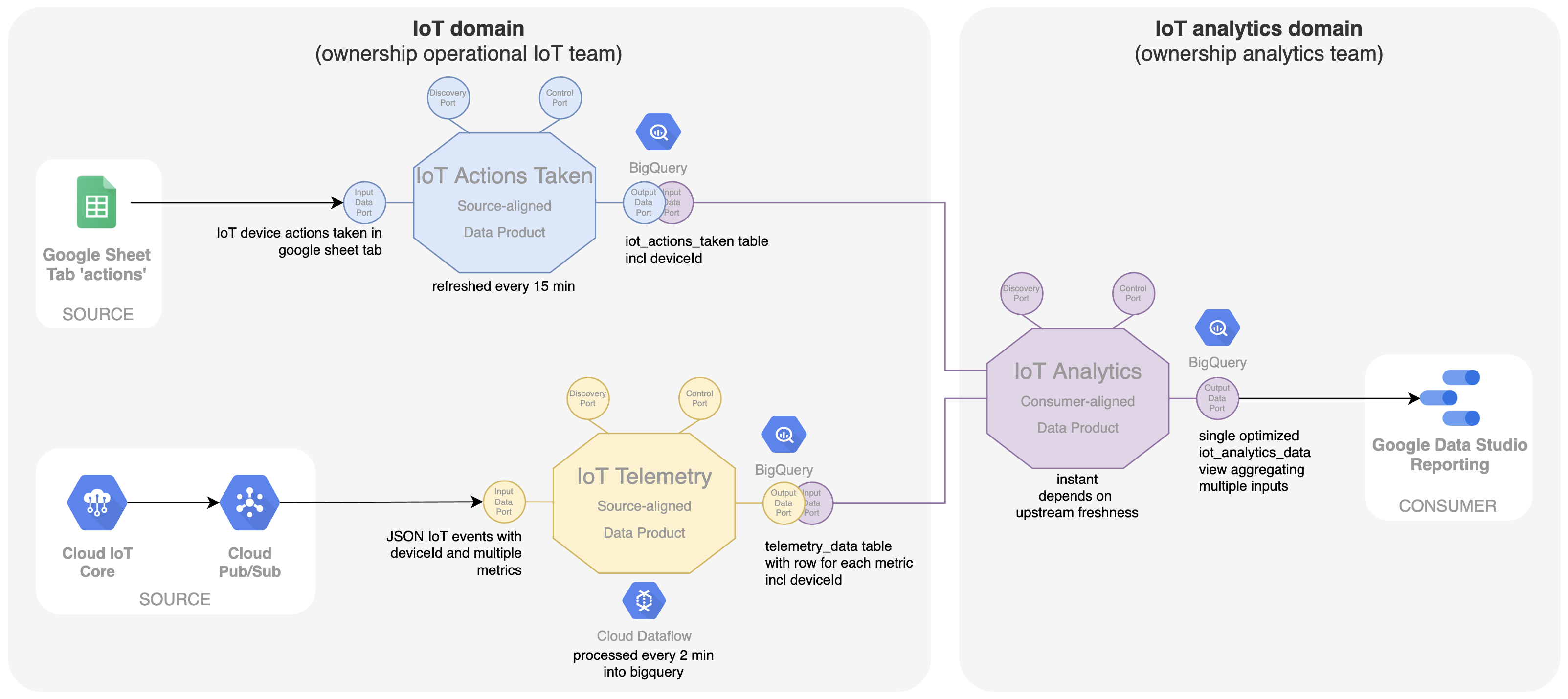
Het bovenstaande schema laat zien dat het analyseteam rechtstreeks de outputpoorten van beide dataproducten gebruikt. Dit is vaak geen optimale oplossing. Het is aangewezen om bij het maken van het dashboard een dataset te gebruiken die alle data combineert die is geoptimaliseerd voor gebruik in dat specifieke dashboard. Hiervoor wordt een consumer-aligned dataproduct 'Iot Analytics' geïntroduceerd (zie hieronder). Data van zowel 'IoT Telemetry' als 'IoT Actions Taken' dataproducten zijn inputpoorten voor dit nieuwe dataproduct. Op basis van de 'device-id' worden de data gecombineerd tot een bevraagbare en geoptimaliseerde SQL-weergave in BigQuery. Het model van dit dataproduct is ook beter afgestemd op de use case, namelijk het dashboard in Google Data Studio. Het analyseteam is eigenaar van het dataproduct. Zo kan het dashboard en de onderliggende geoptimaliseerde datastructuur binnen één team sneller en met meer autonomie gewijzigd worden, wat resulteert in meer business agility.
Daarnaast wordt door eindgebruikers aanvullende metadata over de locatie van het apparaat bijgehouden in een Google-sheet (bijvoorbeeld het aantal personen dat aanwezig is in een kamer, extern CO2-niveau, enz.). Deze data worden ook door het IoT-team vrijgegeven als een afzonderlijk, source-aligned dataproduct genaamd 'IoT Metadata' en door het analyseteam samengevoegd in het dataproduct 'IoT Analytics'.
Er is ook een specifieke vereiste die inhoudt dat een enkel apparaat met een device-id niet exclusief is voor één klant. Na verloop van tijd kan een apparaat worden verplaatst naar een andere klant. Dit betekent dat de oplossing multi-tenancy moet ondersteunen waarbij data (telemetrie, acties, metadata) gescheiden worden gehouden, zodat klanten of tenants alleen de data kunnen zien die relevant was op het moment dat het device bij hen was. Hiervoor is een tenant-id geïntroduceerd als aanvullende data-eigenschap in alle operationele systemen en alle source-aligned dataproducten. Merk op dat voor het dataproduct 'IoT Telemetry' deze tenant-id niet is opgenomen in de data die van de apparaten komen. We kunnen deze tenant-id alleen uit het dataproduct 'IoT Metadata' halen op het moment dat een meting binnenkomt. Het dataproduct 'IoT Metadata' krijgt een extra outputpoort die de mapping van device-id naar tenant-id vergemakkelijkt. Deze poort is dan een extra inputpoort voor het 'IoT Telemetry' dataproduct om ervoor te zorgen dat de tenant-id wordt opgenomen in elke metriek die in de outputpoort wordt geleverd. Het analytics-team kan dan zijn dataproduct 'IoT analytics' en dashboards aanpassen om rekening te houden met deze multi-tenancy.
Het eindresultaat inclusief het metadata dataproduct en multi-tenancy support is hieronder weergegeven.
Er worden afzonderlijke dataproducten gemaakt om elk operationeel systeem of elke dataset beschikbaar te stellen. Waarom gebruiken we niet één dataproduct voor elk domein met meerdere inputpoorten? Er zijn een aantal redenen, afwegingen of design best practices die adviseren om dit niet te doen:
- Dataproducten moeten functioneel zeer samenhangend zijn en de drie operationele systemen hebben te maken met zeer verschillende datasets (telemetrie versus metadata versus actielogboek).
- Door dataproducten te scheiden, krijgen ze een aparte levenscyclus en kunnen ze in hun eigen tempo evolueren, wat meer flexibiliteit biedt.
- Met meerdere dataproducten wordt het mogelijk om de verantwoordelijkheid van bepaalde dataproducten naar andere domeinen of domeinteams te verplaatsen wanneer aanvullende inzichten in die richting wijzen. Hieronder vind je een voorbeeld met betrekking tot de metadata van klanten.
- Het data mesh concept stelt expliciet dat het niet de bedoeling is om slechts één dataproduct per domein te hebben, maar om een logische opsplitsing te ontwerpen in meerdere dataproducten die een domein kan bieden. Een domein kan nogal groot en complex zijn en de verschillende 'hoofdconcepten' zijn typische kandidaten om dataproducten op af te stemmen (cf. ontwerppatroon van 'aggregates' in domain-driven design)
- Voor source-aligned dataproducten die meer op de bron zijn afgestemd, wordt geadviseerd om af te stemmen op concepten in het bronsysteem, in plaats van het te veel af te stemmen op het gebruik en de geaggregeerde weergaven die een dashboard nodig heeft.
- De bovenstaande scheiding maakt ook scenario's mogelijk waarin alleen het dataproduct 'IoT Telemetry' wordt gebruikt en bv. 'IoT Actions Taken’ niet relevant is. Wanneer dit gecombineerd wordt in één groot dataproduct, ontvangt de data afnemer ook de actiedata waarin het niet geïnteresseerd is. Met twee afzonderlijke dataproducten worden deze afhankelijkheden explicieter. Een wijziging aan het dataproduct 'IoT Actions Taken' heeft dan geen invloed op scenario's die alleen gebruikmaken van de 'IoT Telemetry' data.
Even terzijde: in het dataproduct 'IoT-metadata' zijn er eigenlijk twee soorten metadata. Er is metadata over waar het IoT-apparaat zich bevindt (kamer, verdieping, gebouw, ...). Maar er is ook metadata die over de klant of tenant zelf gaat. Waarschijnlijk is er een soort CRM-systeem dat de echte ‘master’ is van de klantdata en waarvan de customer-id gelijk moet zijn aan de tenant-id in onze data-mesh. Een beter domein-ownership en een meer optimale manier van werken zou zijn om het team dat verantwoordelijk is voor het CRM-systeem te vragen om ook een source-aligned 'Customers’ dataproduct te leveren met een customer-id en metadata over de klant. Dan hoeft dit niet meer ingevuld te worden in de Google-sheet met IoT-metadata. Bovendien zou het analyseteam niet alleen meer klantdata krijgen, maar ook nauwkeurigere data omdat deze rechtstreeks van de bron komen.
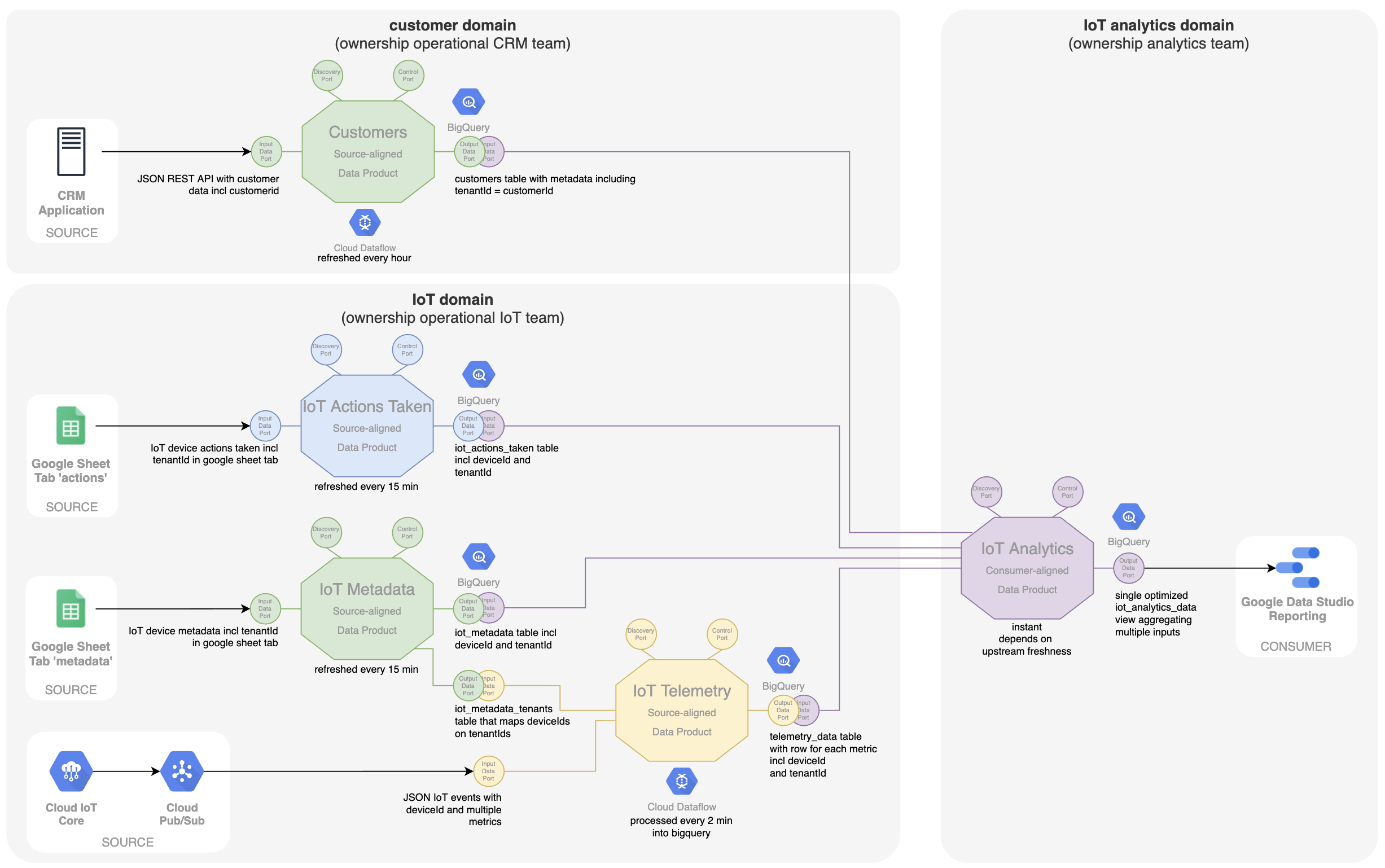
Dit proces illustreert dat het denken in termen van dataproducten als bouwstenen een nuttige ontwerpmethodologie is voor het ontwerpen en ontwikkelen van een dataplatform. De methodologie maakt duidelijk waar het ownership van bepaalde data moet worden gelegd. Dit ownership houdt in dat dit team verantwoordelijk is voor het onderhoud en de evolutie van het dataproduct, afhankelijk van de eisen van de gebruikers en de evolutie van de data in het operationele bronsysteem.
Een pseudo self-service data mesh platform
In deze blogpost hebben we twee data mesh principes lichtjes aangeraakt: ‘domain-oriented ownership’ en ‘data as a product’.
‘Domain-oriented ownership’ gaat domeingrenzen expliciet definiëren en elk dataproduct toewijzen aan een domeinteam.
‘Data as a product’ werd verkend door te denken in termen van 'dataproducten', niet alleen als bouwstenen, maar ook over hoe die data makkelijk gebruikt kan worden.
We hebben de principes van ‘self-serve data platform’ en ‘federated computation governance’ niet besproken in deze blog. Bij de start van je data mesh avontuur is er een heel spectrum om rekening mee te houden, van helemaal geen self-service en automatiseringsmogelijkheden tot een volwaardig geautomatiseerd self-service dataplatform. Laten we dit wat verder illustreren.
In het bovenstaande voorbeeld hebben we het mogelijk gemaakt dat verantwoordelijkheid op technisch niveau aan een domeinteam wordt gegeven. We hebben de code van één dataproduct allemaal in één source code repository gestoken, waar vervolgens één team verantwoordelijk voor kan zijn. Dus alle transformatiecode, infrastructure-as-code, enz. maken deel uit van één code repository.
Voor infrastructure-as-code gebruikten we scripts met de command line interface van Gcloud. Deze scripts zijn ook ingebed in dezelfde code repository en maken het mogelijk om het dataproduct te ontwikkelen, bouwen, configureren, implementeren en wijzigen.
Op infrastructuurniveau maakten we gebruik van het self-service infrastructuurplatform van Google Cloud. De self-service is puur gericht op infrastructuur. Dit geeft te veel flexibiliteit aan ontwikkelteams zonder uniforme sturing en/of controle. Het is echter belangrijk om te waken dat het resulterende data mesh een coherente en consistente verzameling data producten blijft.
In die zin zou het eindresultaat hier een 'pseudo self-service data mesh platform' kunnen worden genoemd op dat spectrum van self-service en automatisering. Het betekent niet noodzakelijk dat we onze doelen niet bereiken. Dit kan voldoende zijn om de voordelen van een data mesh ontwerpmethodologie te hebben en toch te eindigen met een goede architectuur, duidelijk ownership en wendbaarheid om wijzigingen aan te brengen.
Til het naar een hoger niveau
Een volgende stap naar een volwaardig self-service dataplatform is om het abstractieniveau te verhogen waarop een data-product-ontwikkelaar interactie heeft met het self-service platform. Dan beschouw je een 'dataproduct' als de kleinste deploybare architecturale eenheid waarrond automatisering en tooling wordt ontwikkeld om zelfbediening mogelijk te maken.
We kunnen de complexiteit van de infrastructuur wegnemen door declaratieve specificatie en volledige automatisering van zaken als provisioning van opslag en API-endpoints mogelijk te maken. Het doel is om het heel gemakkelijk te maken om data als product te delen, zodat er geen reden is om je data niet als team te delen.
Een andere stap is om ook het data mesh netwerk als geheel te beschouwen en mogelijkheden op mesh-niveau te introduceren, zoals:
- ontdekking van dataproducten via een datacatalogus,
- het automatiseren van governancebeleid om de consistentie en kwaliteit van de data en dataproducten te vergroten, d.w.z. ‘federated computing governance’,
- datakwaliteit en gebruiksstatistieken verzamelen als aanvullende metadata in de datacatalogus,
- ...
Het doel is om het heel gemakkelijk te maken om data te vinden, te selecteren, te consumeren en opnieuw te gebruiken in een optimale gebruikerservaring van het dataplatform.
Hoe ver je gaat in dit data mesh avontuur met betrekking tot self-service dataplatform tooling en automatisering, hangt af van de complexiteit van de use cases, de schaal van de organisatie, de technische vaardigheden van data-product-ontwikkelaars, de beschikbare financiering, de visie voor de toekomst, en nog veel meer.
Kortom: het hangt ervan af, en is een onderwerp voor toekomstige blogposts. 😉
Ben jij ook bezig met je data mesh avontuur en wil je ideeën delen? Of wil je starten met data mesh en heb je advies nodig? Worstel je met de architectuur van je dataplatform? Aarzel niet om contact op te nemen met ons geweldig team!
Wil je meer weten of Data Mesh?











