.svg?width=174&auto=compress,webp&upscale=true)
.svg?width=139&auto=compress,webp&upscale=true)

Leestijd 8 min
Peter Jans

Stel, je bent een Product Owner in een Agile delivery team, klaar om aan de slag te gaan met je product. Om dat te kunnen doen, moet je je ontwikkelteam een doel geven en een lijst met dingen om aan te werken. Als je SCRUM als raamwerk gebruikt, noem je die lijst met dingen om aan te werken een Product Backlog. Uit de SCRUM-gids:
Oké, je moet dus beginnen met een backlog, prioriteiten stellen en dan de items met de hoogste prioriteit eerst bouwen. SCRUM - en Agile ontwikkeling in het algemeen - is zowel incrementeel als iteratief (zie hier of hier voor een goede uitleg van die termen). Laten we dit illustreren met een voorbeeld: als een klant een auto bestelt - en we gebruiken SCRUM om hem te implementeren - kunnen we itereren op het chassis en de auto incrementeel bouwen, zoals dit:
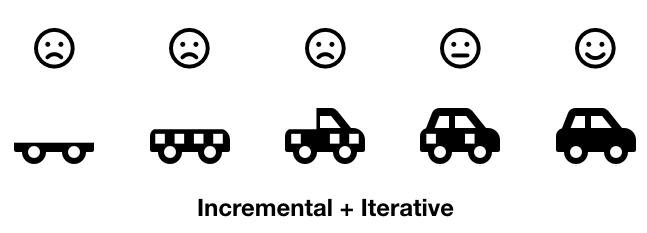
Als Product Owner(de rol die je inneemt als Product Manager) zit je echter met een paar vragen:
In deze blogpost proberen we die vragen geleidelijk te beantwoorden.
Laten we beginnen met de tweede vraag op onze lijst: hoe kan ik er zeker van zijn dat het een behoefte van de eindgebruiker oplost? Henrik Kniberg wijst er terecht op:
We beginnen met dezelfde context - de klant heeft een auto besteld. Maar deze keer bouwen we niet gewoon een auto. In plaats daarvan richten we ons op de onderliggende behoefte die de klant vervuld wil zien. Blijkt dat zijn onderliggende behoefte is "Ik moet sneller van A naar B", en een auto is slechts één mogelijke oplossing daarvoor.
Vergeleken met ons vorige voorbeeld van een klant die een auto bestelt, zou het er nu zo uitzien:

Simpel gezegd betekent dit dat je eerst het echte probleem moet ontrafelen en naar eigen inzicht moet aanpassen. Het ontrafelen van het probleem is iteratief van aard: zolang je geen bevestiging krijgt dat je een echte behoefte aan het oplossen bent, moet je veranderen en aanpassen. Je presenteert de eindgebruiker een beste schatting van hoe een oplossing eruit zou kunnen zien. Zolang de gebruiker niet tevreden is, moet je dieper graven en met alternatieven komen. Uiteindelijk raak je de 'sweet spot' en krijg je de bevestiging dat je het probleem hebt begrepen. Deze bevestiging kan gebaseerd zijn op echte gebruiksgegevens, kwalitatieve inzichten of een combinatie van beide.
SCRUM geeft niet aan hoe je Henriks idee moet implementeren. Ik heb begrepen dat er een voorkeur is voor het ontwikkelen van software en het richten van de sprint op het eindigen met een increment. Dit betekent dat werkende software wordt gebruikt als artefact tijdens de iteratie om het probleem te definiëren. Het nadeel is echter dat het team reeds geïmplementeerde incrementen opnieuw moet bewerken, omdat ze moeten worden aangepast aan nieuwe inzichten. Ik heb de verspillingen van softwareontwikkeling gecontroleerd en de potentiële verspillingen geïdentificeerd:
Dit zijn nog steeds aandachtspunten die kunnen worden opgelost door een goede productontdekkingsstap.
Laten we eerst nog eens kijken naar de vragen waar een Product Owner mee kan zitten en aangeven welke we hebben opgelost:
Om de potentiële verspilling in het voorbeeld van Henrik te elimineren, moet je het iteratieve deel (uitzoeken wat de gebruiker nodig heeft) en het bouwen van de software (een oplossing voor het probleem maken) opsplitsen.Uitzoeken wat de gebruiker nodig heeft, houdt een zogenaamde ontdekkingsstap in.
Marty Cagan, de "meest invloedrijke persoon in de productruimte",is het hiermee eens:
In Henriks voorbeeld is het team bezig om tegelijkertijd te bepalen wat het juiste product is om te bouwen en om dat product te bouwen. En ze hebben één belangrijk hulpmiddel tot hun beschikking om dat te doen: de ingenieurs. Dus wat je ziet is een progressief ontwikkeld product, met een belangrijke nadruk op iets dat we bij elke iteratie kunnen testen op echte gebruikers.
Henrik benadrukt dat ze bouwen om te leren, maar ze doen dit met het enige gereedschap dat ze denken te hebben: ingenieurs die code schrijven. Als je goed leest, vermeldt Henrik dat de ingenieurs eigenlijk geen producten hoeven te bouwen - ze zouden prototypes kunnen bouwen, maar bij de meeste teams die ik ontmoet, gaat dit punt verloren omdat ze niet begrijpen dat er veel vormen van prototypes zijn, waarvan de meeste niet bedoeld zijn om door ingenieurs te worden gemaakt.
Dat klopt: het schrijven van software kan een goede oplossing zijn om erachter te komen wat de gebruiker wil, maar meestal is het de duurste manier om er te komen.
Met een ontdekkingsstap kun je je richten op de doelstellingen van een product: is het waardevol, bruikbaar, haalbaar en levensvatbaar? Deze stap is meestal iteratief. Het eindresultaat is een duidelijke probleemdefinitie en dus een mogelijke oplossing voor dat probleem; een oplossing met een hoge waarschijnlijkheid om de behoefte van een gebruiker op te lossen. Omdat je een ontdekkingsstap hebt genomen, betekent dit dat je het echte probleem kunt beschrijven aan het engineeringteam. Je kunt het probleem ook gedetailleerder beschrijven en ook beschrijven wat voor eigenschappen je verwacht van de eindoplossing, bijvoorbeeld een fitnessfunctie die de oplossing in context plaatst. De ontwikkelteams zoeken dan uit hoe ze die oplossing moeten bouwen. Dit is de opleveringsstap en deze is meestal incrementeel.
Bij de productontdekkings- en leveringsstappen zijn er twee sporen die het team moet overwegen: een productontdekkingsspoor en een leveringsspoor.

Laten we de vragen van de Product Owner een derde keer opnieuw bekijken en aangeven welke we hebben opgelost:
Ontdekkingswerk richt zich op snel leren en valideren. Maar hoe koppel je dat aan het opleveringswerk? Als een project begint, doe je misschien eerst discovery en laat je - iets later - het engineeringteam beginnen.

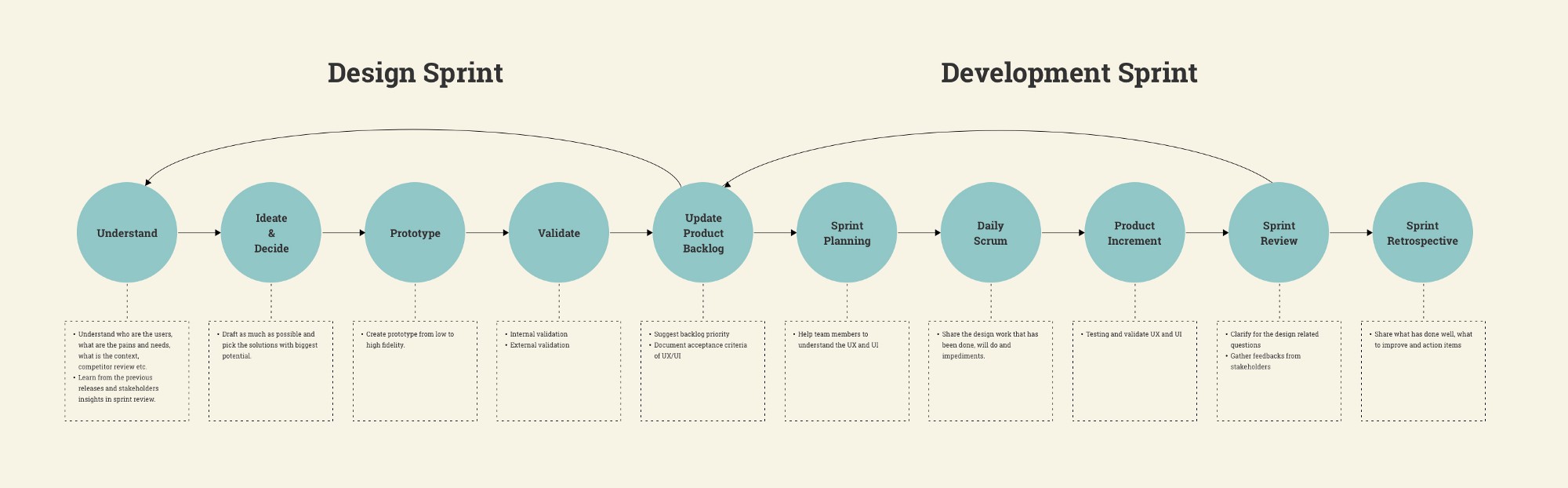
Dat lijkt veel op Waterfall! Maar zo hoeft het niet te zijn. Jeff Patton, een veteraan Product Manager en schrijver van het boek User Story Mapping, zegt dat het allemaal tegelijk gebeurt (Dual Track). In plaats van een waterval krijgen we een loop. Een lus voor ontdekkend leren ziet er ongeveer zo uit:
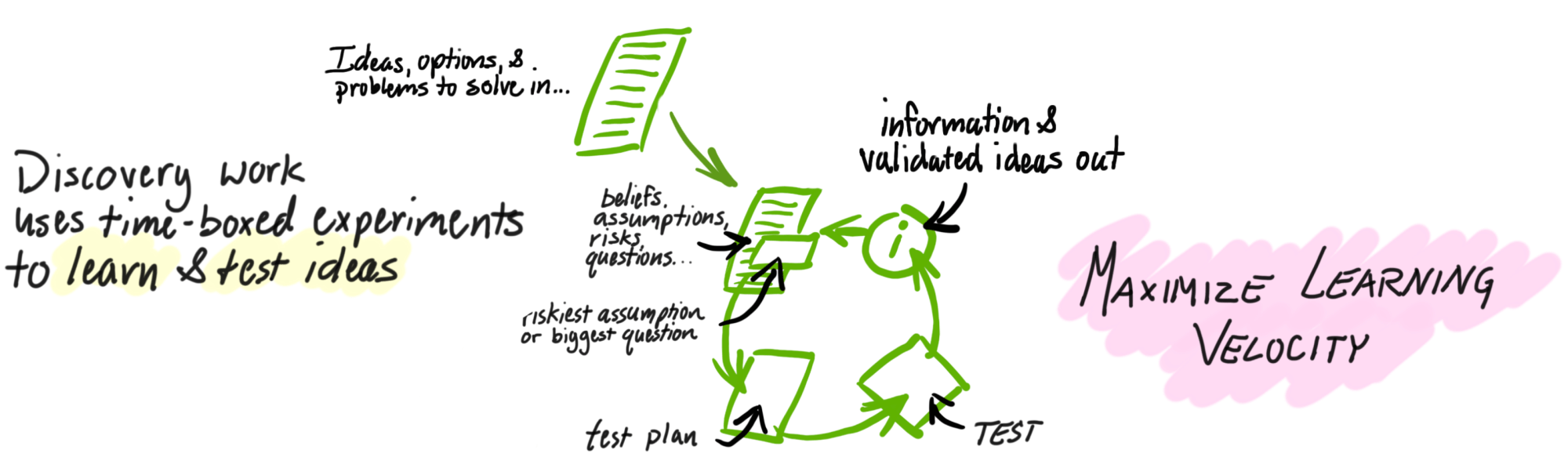
Het begint met het beschrijven van
Productontdekkingssessies lopen als volgt in elkaar over:
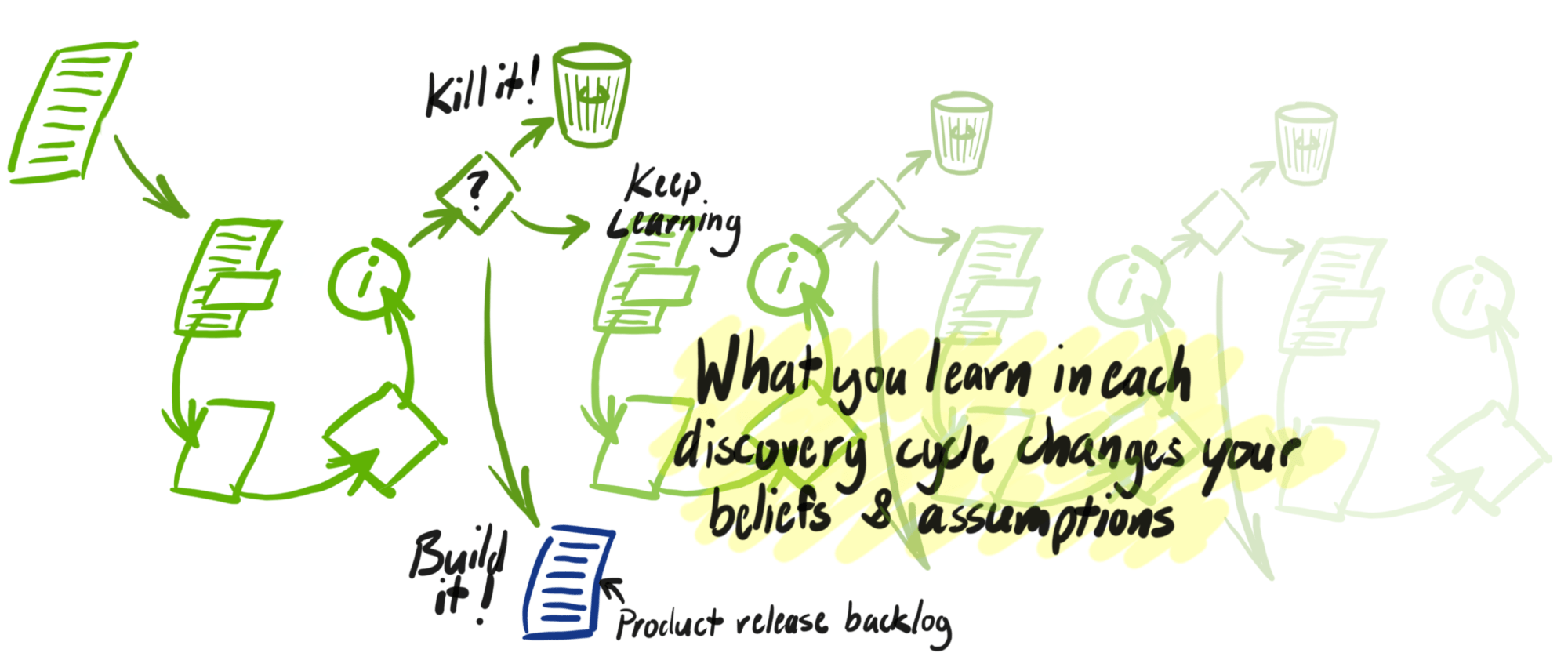
Ontdekkingswerk maakt gebruik van onregelmatige cycli. Het is 'lean' in de zin dat we proberen de ontdekkingscyclus zo kort mogelijk te maken. Ontdekideeën muteren en worden vaak verlaten, wat de beste stap is naar meer doelbewuste ontwikkelingscycli.
Om potentiële risico's te elimineren, moet je je bewust zijn van zowel de ontdekkingsstap als de opleveringsstap. De ontdekkingsstap richt zich op de doelstellingen van een product: waarde, bruikbaarheid, haalbaarheid en levensvatbaarheid en is meestal iteratief. De opleveringsstap richt zich op hoe je een product bouwt en is meestal incrementeel. Hoewel de stappen gescheiden zijn, vinden de sporen tegelijkertijd plaats, wat we Dual Track noemen.
Het artikel van Jeff Patton over Dual Track noemt ook een paar belangrijke punten.
De twee sporen worden parallel uitgevoerd:
Het spoor stopt niet zodra je een probleem hebt ontdekt om op te lossen. Het volgende probleem loert al om de hoek. In ons voorbeeld met de klant die een auto bestelt ("Ik moet sneller van A naar B"), zouden we ook kunnen denken dat de gebruiker onderdak nodig heeft, wat kan variëren van een eenvoudige hut tot een kasteel.
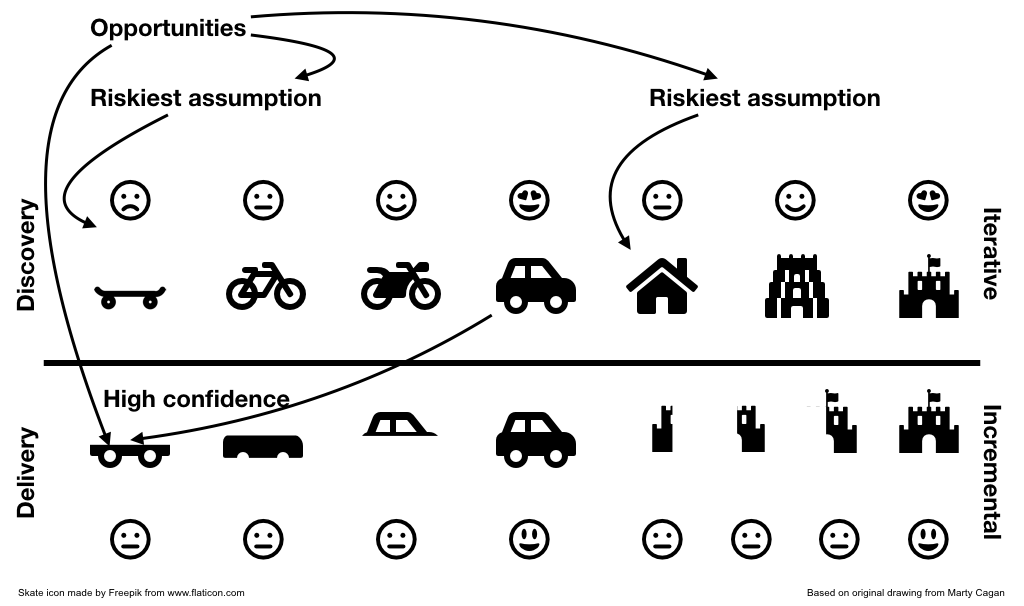
Een laatste opmerking: deze blogpost begon met SCRUM als het raamwerk voor oplevering, maar de methodologie doet er niet echt toe: het zou Kanban, Crystal XP en zelfs Waterval kunnen zijn, zolang het team maar in staat is om gelijke tred te houden met de twee sporen. Maar omdat het ontdekkingsgedeelte gericht is op snelleren , past een Agile methodologienatuurlijk beter.
Laten we de vragen van de Product Owner nog een laatste keer bekijken en aangeven welke nu zijn opgelost.


Bij de ontwikkeling van software kunnen aannames ernstige gevolgen hebben en we moeten altijd op onze hoede zijn. In deze blogpost bespreken we hoe je omgaat met aannames bij het ontwikkelen van software. Stel je voor... je rijdt naar een bepaalde pl
Lees verder

ACA doet veel projecten. In het laatste kwartaal van 2017 deden we een vrij klein project voor een klant in de financiële sector. De deadline voor het project was eind november en onze klant werd eind september ongerust. We hadden er echter alle vert
Lees verder

OutSystems: een katalysator voor bedrijfsinnovatie In het snelle zakelijke landschap van vandaag de dag moeten organisaties innovatieve oplossingen omarmen om voorop te blijven lopen. Er zijn veel strategische technologische trends die cruciale bedri
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
