.svg?width=174&auto=compress,webp&upscale=true)
.svg?width=139&auto=compress,webp&upscale=true)

6 MEI 2025
Leestijd 4 min
Stijn Vandereyken

Binnen ACA werken meerdere teams aan verschillende (of dezelfde!) projecten. Elk team heeft zijn eigen expertisedomeinen, zoals het ontwikkelen van software op maat, marketing en communicatie, mobiele ontwikkeling en meer. De teams die gespecialiseerd zijn in Atlassian-producten en cloud-expertise combineerden hun kennis om een zeer beschikbare Atlassian-stack op Kubernetes te creëren. Niet alleen konden we op deze manier onze interne processen verbeteren, we konden deze oplossing ook aan onze klanten aanbieden!
In deze blogpost leggen we uit hoe onze Atlassian- en cloudteams een hoogbeschikbare Atlassian-stack bovenop Kubernetes hebben gebouwd. We bespreken ook de voordelen van deze aanpak en de problemen die we onderweg zijn tegengekomen. Hoewel we er verdomd dichtbij zijn, zijn we toch niet perfect 😉 Tot slot bespreken we hoe we deze setup monitoren.
Onze Atlassian stack bestaat uit de volgende producten:
Zoals je kunt zien, gebruiken we AWS als cloud provider voor onze Kubernetes setup. We maken alle resources aan met Terraform. We hebben een aparte blogpost geschreven over hoe onze Kubernetes setup er precies uitziet. Je kunt het hier lezen! De afbeelding hieronder zou je een algemeen idee moeten geven.
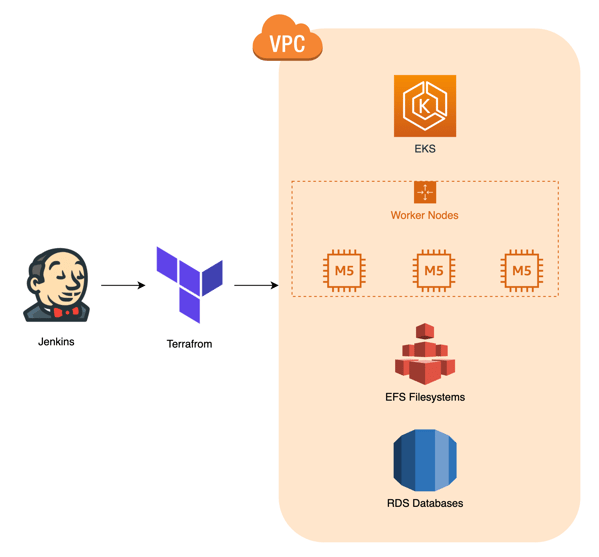
Het volgende diagram geeft je een idee van de opzet van ons Atlassian Data Center.
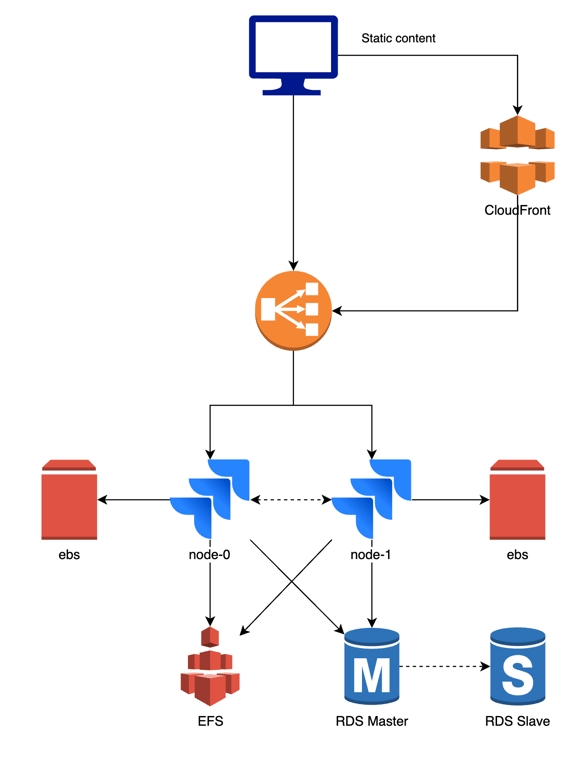
Hoewel er een paar verschillen zijn tussen de producten en de opstellingen, blijft de kern hetzelfde.
Door deze opzet te gebruiken, kunnen we gebruikmaken van de voordelen van Docker en Kubernetes en de datacenterversies van de Atlassian-tooling. Er zijn veel voordelen verbonden aan deze manier van werken, maar we hebben de belangrijkste voordelen hieronder opgesomd.

Geïnteresseerd om zelf de kracht van Kubernetes te benutten? Op onze website vind je meer informatie over hoe we je kunnen helpen!
De migratie naar deze stack was niet alleen maar leuk en aardig. We zijn onderweg zeker een aantal moeilijkheden en uitdagingen tegengekomen. Door ze hier te bespreken, hopen we dat we jouw migratie naar een vergelijkbare setup kunnen vergemakkelijken!

We gebruiken de volgende tools om alle resources binnen onze setup te monitoren
Als onze monitoring een afwijking detecteert, wordt er een alert aangemaakt binnen OpsGenie. OpsGenie zorgt ervoor dat deze waarschuwing naar het team of de oproepkracht wordt gestuurd die verantwoordelijk is voor het oplossen van het probleem. Als de oproepkracht de waarschuwing niet op tijd bevestigt, wordt de waarschuwing geëscaleerd naar het team dat verantwoordelijk is voor die specifieke waarschuwing.
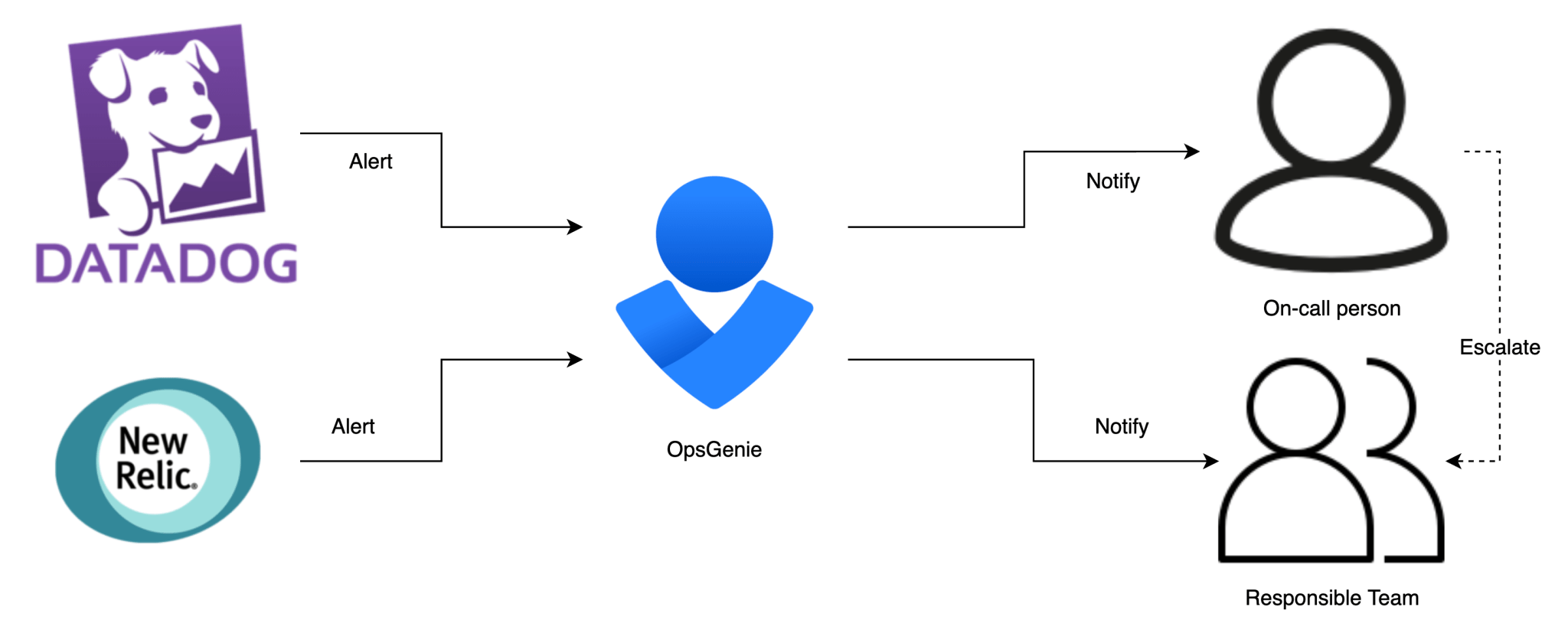
Kortom, we zijn erg blij dat we zijn overgestapt op deze nieuwe stack. De combinatie van de voordelen van Kubernetes en de Atlassian Data Center versies van Jira, Confluence en BitBucket voelt als een grote stap in de goede richting. We hebben elke dag profijt van de verbeteringen op het gebied van self-healing, deployment en monitoring en het onderhoud is een stuk eenvoudiger geworden.
Geïnteresseerd in je eigen Atlassian Stack? Wil je ook de kracht van Kubernetes benutten? Op onze website vind je meer informatie over hoe we je kunnen helpen!

ACA Group was aanwezig op SUSECON 2026, samen met meer dan 2.000 deelnemers. Eén ding werd meteen duidelijk: SUSE zit stevig in de lift in Europa, vooral rond digitale soevereiniteit, AI en edge computing.
Lees verder
Een paar jaar geleden voelde AI als een fantastische gimmick. Vorige week in Amsterdam viel die illusie volledig in duigen. Ik maak al vele jaren deel uit van het circus dat de IT-sector soms is. Net wanneer je denkt dat je alles wel gezien hebt, haa
Lees verder

AWS Quick is Amazon's antwoord op een probleem dat bijna elke zakelijke gebruiker kent: AI-tools die vragen kunnen beantwoorden, maar geen acties kunnen uitvoeren. AWS Quick is anders. Het is een agentisch AI-platform dat meerstapsworkflows automatis
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
