


Is het Data Lake vs. Data Mesh? Of kunnen ze elkaar aanvullen?
In de voorbije jaren heeft de exponentiële toename van data geleid tot een groeiende vraag naar betere manieren om deze te beheren. De uitbouw van een datagedreven bedrijf blijft dan ook een van de belangrijkste strategische doelstellingen van heel wat zakelijke stakeholders. Hoewel het logisch lijkt dat bedrijven het idee om datagedreven te zijn omarmen, blijkt de uitvoering hiervan veel moeilijker.
Data Mesh en Data Lakes zijn 2 belangrijke concepten in de wereld van data-architecturen die samen een flexibele en schaalbare benadering van databeheer kunnen verzekeren. Data Lakes hebben al bewezen een populaire oplossing te zijn, maar ook belangstelling voor Data Mesh groeit. Deze blog verdiept zich in de 2 concepten en onderzoekt hoe ze elkaar kunnen aanvullen.

Data Lakes
Een Data Lake is een grote en centrale opslag-repository die enorme hoeveelheden data bevat afkomstig van verschillende bronnen en in verschillende dataformaten. In een Data Lake kan getructureerde, semi gestructureerde en ongestructureerde data (bv. afbeeldingen) worden opgeslagen.
Je kunt het voorstellen als een gigantische plas water, waarin je allerlei soorten data kan opslaan, zoals klantgegevens, transactiegegevens, social media feeds, afbeeldingen, video's, ... . Het is een budgetvriendelijke en toegankelijke oplossing voor bedrijven die te maken krijgen met grote data volumes en verschillende formaten van data.
Bovendien kunnen teams dankzij Data Lakes met ruwe data aan de slag gaan, zonder uitgebreide preprocessing of normalisatie.
Data Mesh
Data Mesh is een vrij nieuw concept dat een gedecentraliseerde benadering van databeheer hanteert. Het behandelt data als een product en wordt beheerd door autonome teams die verantwoordelijk zijn voor een bepaald domein.
Volgens de Data Mesh-benadering moet data in het bezit zijn van en beheerd worden door de mensen die ze het best begrijpen - de domeinexperts - en moeten ze behandeld worden als een product. Dat betekent dat elk team verantwoordelijk is voor de kwaliteit, de betrouwbaarheid en de toegankelijkheid van de data binnen zijn domein.
Het resultaat? Een meer schaalbare en flexibele benadering van databeheer, waarbij teams onafhankelijke beslissingen kunnen nemen over hun data, zonder tussenkomst van een gecentraliseerd datateam.
Hoe kan een Data Lake-technologie gebruikt worden in een Data Mesh-benadering?
Kort samengevat is een Data Mesh een architectuur waarbij data eigendom is van en beheerd is door individuele teams, met een gedecentraliseerde benadering van databeheer als resultaat. Een Data Lake is een technologie die een gecentraliseerde opslagoplossing biedt, waardoor teams grote hoeveelheden gegevens kunnen opslaan en beheren, zonder zich te bekommeren om de datastructuur of het dataformaat.
In Data Mesh draait decentralisatie om het eigenaarschap van het delen van data als een product op een gedecentraliseerde manier te organiseren. Er wordt daarbij niet afgezien van gedecentraliseerde opslagoplossingen, zoals Data Lakes, maar wel worden ze gebruikt op een manier die aansluit bij de principes van Data Mesh.
Data Mesh gaat over de bepalen en het beheren van dataproducten als een bouwsteen om data gemakkelijk toegankelijk en herbruikbaar te maken in verschillende gebruikssituaties. Elk 'dataproduct' moet zijn data op meerdere manieren kunnen aanbieden via verschillende outputpoorten.
Een outputpoort is bedoeld om gegevens op een natuurlijke manier toegankelijk te maken voor een specifieke gebruikssituatie. Voorbeelden van gebruikssituaties zijn analyse en rapportering, machine learning, verwerking van data in real time, ... . Meerdere soorten outputpoorten hebben dan ook overeenkomstige datatechnologieën nodig die een specifieke toegangsmodus mogelijk maken.
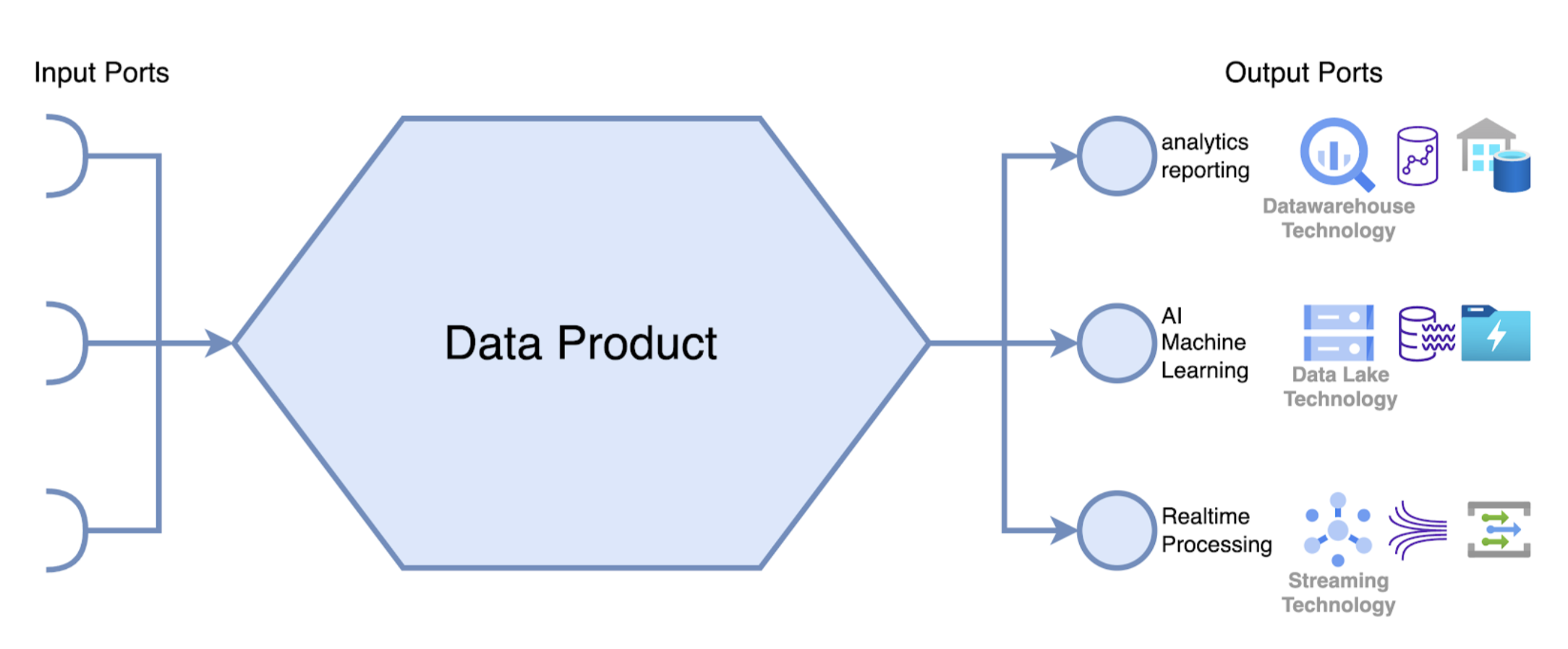
Een van die technologieën die een Data Mesh-architectuur kan ondersteunen, is een Data Lake. De data in een outputpoort voor een dataproduct kan worden opgeslagen in een Data Lake. Dit type outputpoort kan dan rekenen op alle voordelen die de Data Lake-technologie biedt.
In een Data Mesh-architectuur krijgt elk dataproduct een eigen segment in het Data Lake (bv. een S3 bucket). Dit segment doet dienst als outputpoort voor het dataproduct, waar het team dat verantwoordelijk is voor het dataproduct, zijn data naar het Lake kan schrijven. Door het Data Lake op deze manier te segmenteren, kunnen teams hun eigen data beheren en beveiligen zonder in conflict te komen met andere teams. Hierdoor wordt gedecentraliseerd eigendom mogelijk, zelfs bij gebruik van een meer gecentraliseerde opslagtechnologie.
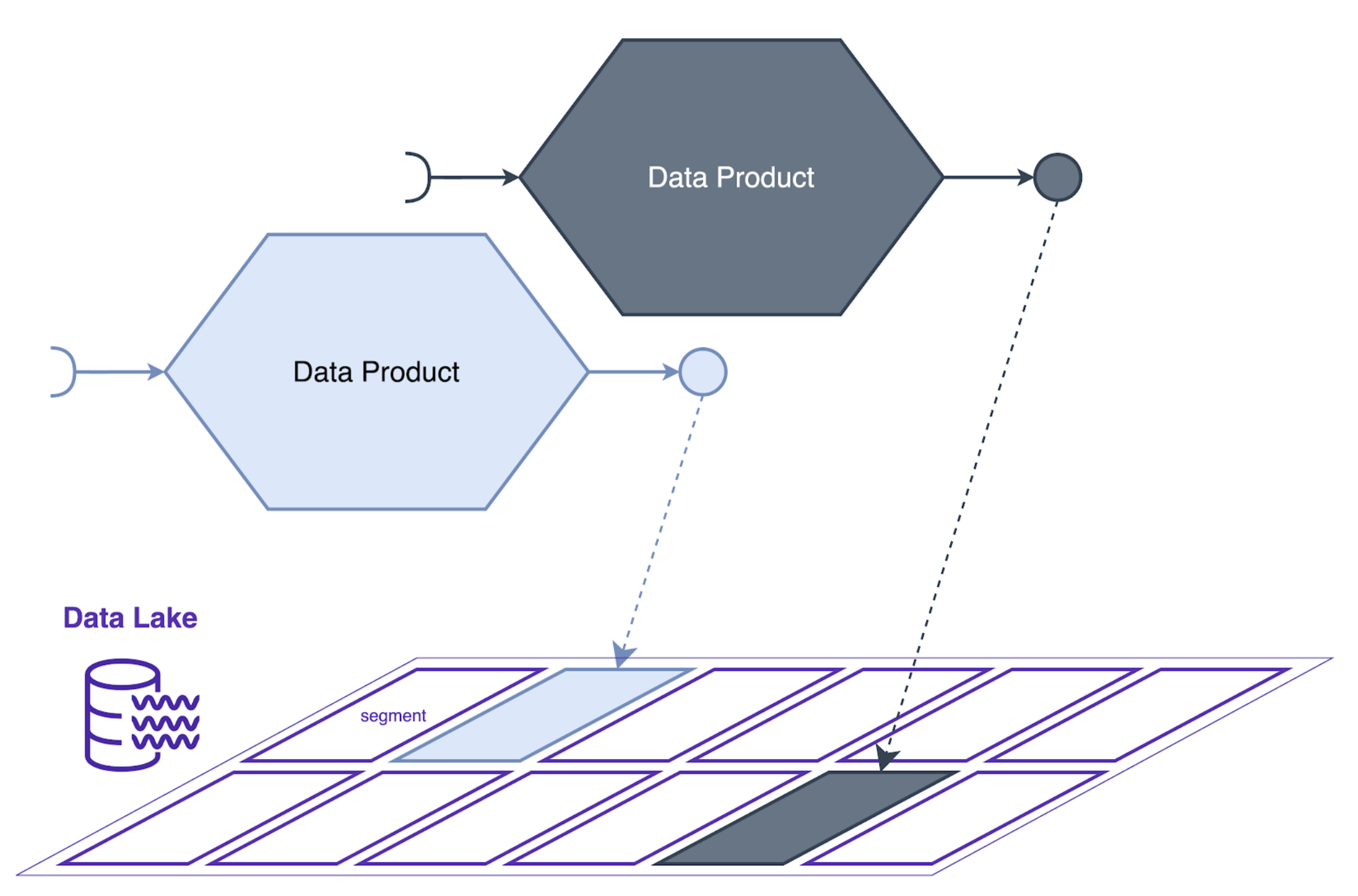
Hoewel een Data Lake een belangrijke technologie is om een Data Mesh-architectuur te ondersteunen, is het misschien niet de perfecte oplossing voor elke gebruikssituatie. Het gebruik van een Data Lake als enige type dataopslagtechnologie kan de flexibiliteit van het Data Mesh-platform beperken, omdat het slechts één soort opslag biedt. Voor business intelligence en rapportering, bijvoorbeeld, kan een datawarehouse-technologie met opslag in tabelvorm geschikter zijn. Nog een voorbeeld is wanneer time series databases of graph databases een beter alternatief zijn omwille van het type data dat we op een natuurlijke manier herbruikbaar willen maken.
Om het Data Mesh-platform flexibeler te maken, moet het de mogelijkheid bieden om verschillende soorten dataopslagtechnologie te integreren. Die vormen elk een ander type outputpoort. Op die manier kan elk dataproduct zijn eigen outputpoorten hebben, met verschillende soorten dataopslagtechnologieën gericht op specifieke datagebruikspatronen.
We stellen vast dat cloud vendors vaak aanraden om een Data Mesh-oplossing te implementeren met een van hun bestaande Data Lake-diensten. Meestal bestaat hun aanpak uit het segmenteren van deze diensten met behulp van beveiligingsrechten. De segmenten zijn dan eigendom van verschillende domeinteams.
De referentiearchitecturen die ze aanbieden, bevatten echter maar één opslagtechnologie, namelijk hun eigen Data Lake-technologie. Het resulterende Data Mesh-platform is bijgevolg minder aanpasbaar en gebonden aan één enkele technologie. Wat ontbreekt, is een expliciete 'dataproduct' abstractie die verder gaat dan alleen het opleggen van beveiligingsgrenzen en die de integratie van verschillende dataopslagtechnologieën en -oplossingen mogelijk maakt.
Conclusie
Databeheer is een cruciaal onderdeel van elke organisatie. Er zijn verschillende technologieën en aanpakken beschikbaar, zoals Data Lakes, datawarehouses, data vaults, time series databases, graph databases, ... En die hebben stuk voor stuk hun eigen troeven en beperkingen.
Uiteindelijk komt het erop neer dat een geslaagde Data Mesh-architectuur de flexibiliteit verzekert om data te delen en te hergebruiken met de juiste technologie voor de juiste gebruikssituatie. Een Data Lake mag dan wel een krachtige tool zijn voor het beheer van ruwe data, het is wellicht niet de beste oplossing voor alle soorten datagebruik.
Door verschillende soorten dataopslagtechnologieën te overwegen, kunnen teams de oplossing kiezen die het best aansluit bij hun specifieke noden en kunnen ze hun workflows voor databeheer optimaliseren. Dankzij het gebruik van dataproducten in een Data Mesh kunnen teams een flexibele en schaalbare architectuur creëren die zich kan aanpassen aan veranderende noden op het vlak van databeheer.
Meer weten over Data Mesh of Data Lakes?











