.svg?width=174&auto=compress,webp&upscale=true)
.svg?width=139&auto=compress,webp&upscale=true)

Reading time 10 min
ACA Group Team

Over the past few months, Kubernetes has become a more mature product and setting up a cluster has become a lot easier. Especially with the official release of Amazon Elastic Container Service for Kubernetes (EKS) on Amazon Web Services, another major cloud provider is able to provide a Kubernetes cluster with a few clicks.
While the complexity of creating a Kubernetes cluster has decreased drastically, there still are some challenging tasks when setting up the resources within the cluster. The biggest challenge for us has always been providing reliable monitoring and logging for the components within the cluster. Since we’ve migrated to Datadog, things have changed for the better. In this blog post, we’ll teach you how to monitor your Kubernetes cluster with Datadog.
For this blog post, we’ll assume you have an active Kubernetes setup and kubectl configured. Our cloud services team prefers the following Kubernetes setup:
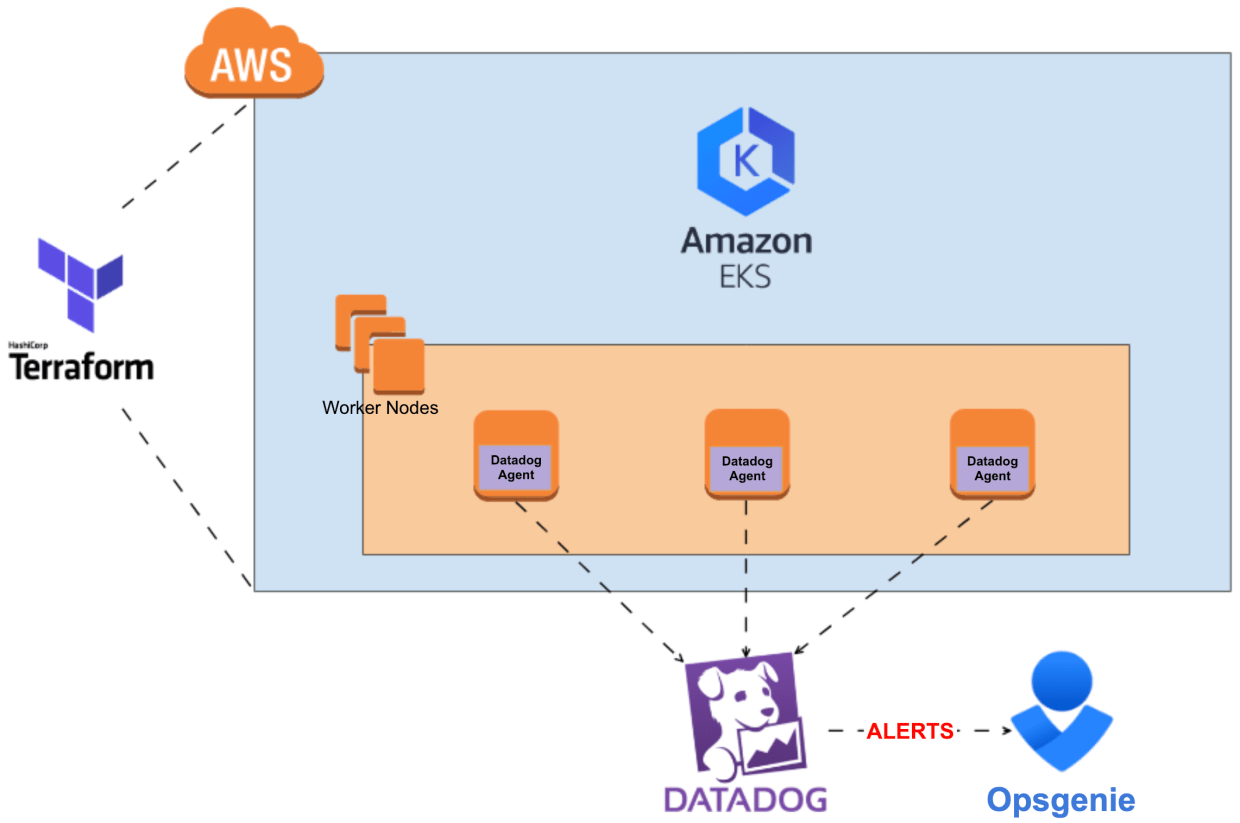
Of course, you’re free to choose your own tools. One requirement, however, is that you must use Datadog (else this whole blog post won’t make a lot of sense). If you’re new to Datadog, you need to create a Datadog account. You can try it out for 14 days for free by clicking here and pressing the “Get started” button. Complete the form and login to your newly created organization. Time to add some hosts!

A Kubernetes DaemonSet makes sure that a Docker container running the Datadog agent is created on every worker node (host) that has joined the Kubernetes cluster. This way, you can monitor the resources for all active worker nodes within the cluster. The YAML file specifies the configuration for all Datadog components we want to enable:
If you wonder what the file looks like, this is it:
Since we use EKS, the master plane is maintained by AWS. Therefore we don’t want any Datadog agent pods to run on the master nodes. Uncomment this if you want to monitor your master nodes, for example when you are running Kops.
We use the JMX-enabled version of the Datadog agent image, which is required for Kafka and Zookeeper integrations. If you don’t need JMX, you should use Datadog/agent:latest as this image is less resource-intensive.
We specify “imagePullPolicy: Always” so we are sure that on startup, the image labelled “latest” is pulled again. In other cases when a new “latest” release is available, it won’t get pulled as we already have an image tagged “latest” available on the node.
We use SealedSecrets, which stores the Datadog API Key. It also sets the environment variable to the value of the Secret. If you don’t know how to get an API Key from Datadog, you can do that here. Enter a useful name and press the “Create API” button.
This ensures the Datadog logs agent is enabled.
This enables autodiscovery and JMX, which we need for our Zookeeper and Kafka integration to work, as it will use JMX to collect data. For more information on autodiscovery, you can read the Datadog docs here.
After enabling JMX, the memory usage of the container drastically increases. If you are not using the JMX version of the image, half of these limits should be fine.
To add some custom configuration, we need to override the default Datadog.yaml configuration file. The ConfigMap has the following content:
The first ConfigMap called Datadogtoken is required to have a persistent state when a new leader is elected. The content of the dd-agent-config ConfigMap is used to create the Datadog.yaml configuration file. We specify and add some extra tags to the resources collected by the agent, which is useful to create filters later on.
When having a Kubernetes cluster with a lot of nodes, we’ve seen containers being stuck in a CrashLoopBackOff status. It’s therefore a good idea to do a more advanced health check to see whether your containers have actually booted. Make sure the health checks start polling after 60 minutes, which seems to be the best value.
Once you have gathered all required configuration in your ConfigMap and DaemonSet files, you can create the resources using your Kubernetes CLI.
After a few seconds, you should start seeing logs and metrics in the Datadog GUI.
Datadog has a range of powerful monitoring features. The host map gives you a visualization of your nodes over the AWS availability zones. The colours in the map represent the relative CPU utilization for each node, green displaying a low level of CPU utilization and orange displaying a busier CPU.
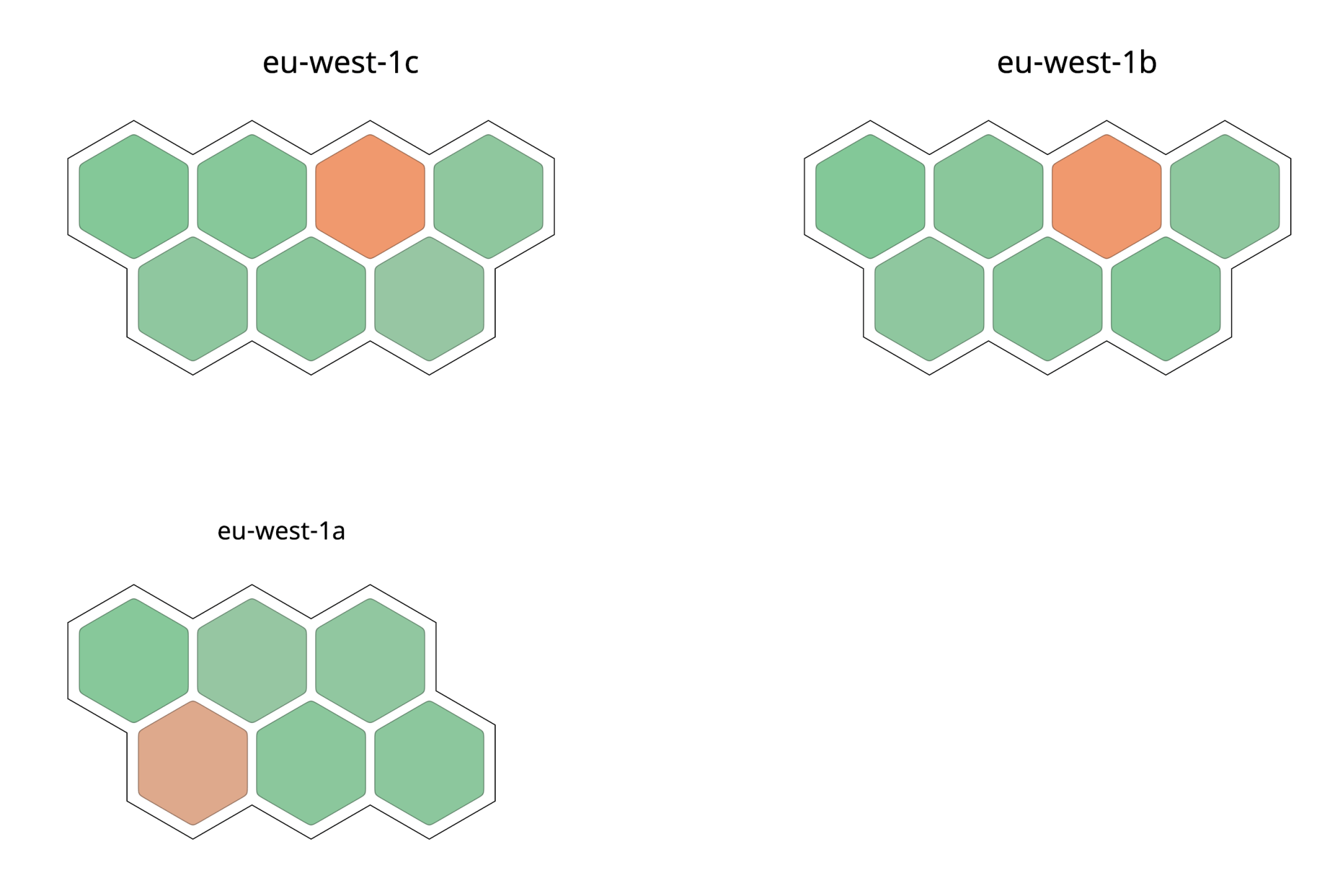
Each node is visible in the infrastructure list. Selecting one of the nodes reveals its details. You can monitor containers in the container view and see more details (e.g. graphs which visualize a trend) by selecting a specific container. Last but not least, processes can be monitored separately from the process list, with trends visible for every process. These fine-grained viewing levels make it easy to quickly pinpoint problems and generally lead to faster response times.
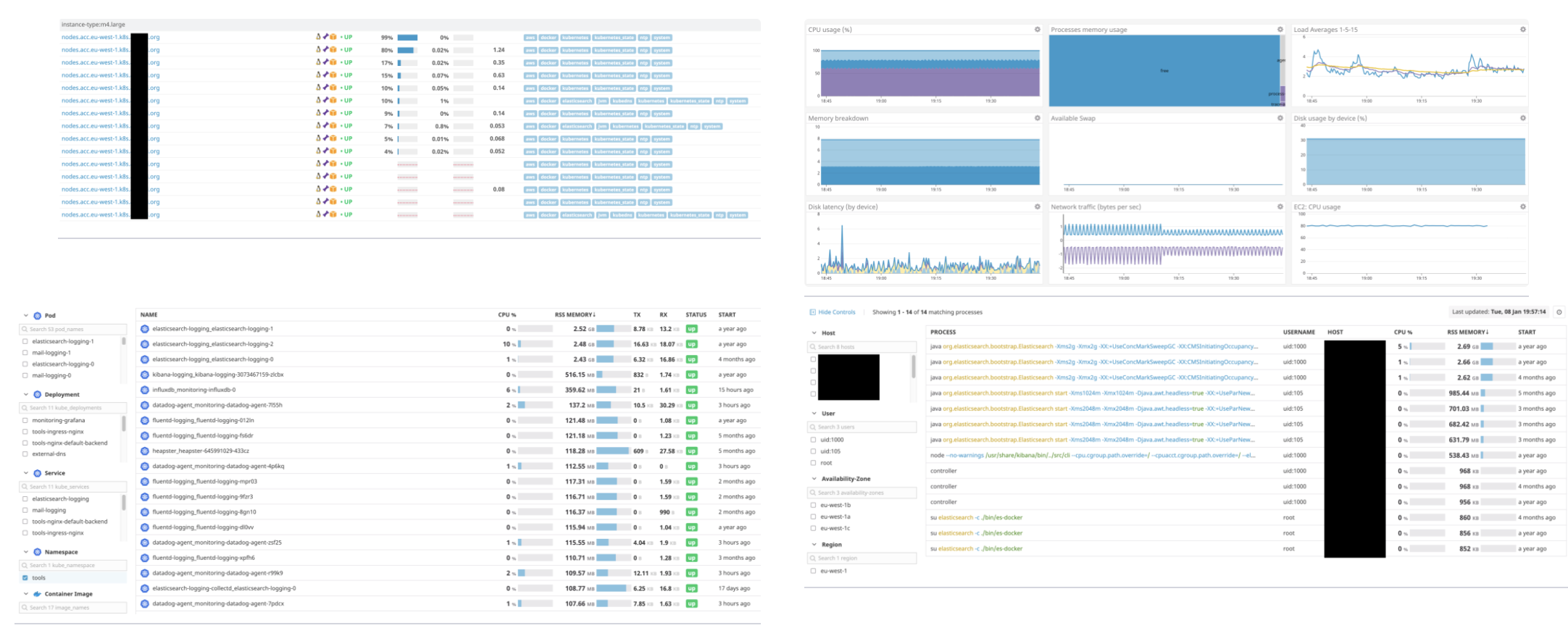
All data is available to create beautiful dashboards and good monitors to alert on failures. The creation of these monitors can be scripted, making it fairly easy to set up additional accounts and setups. Easy to see why Datadog is indispensable in our solutions… 😉
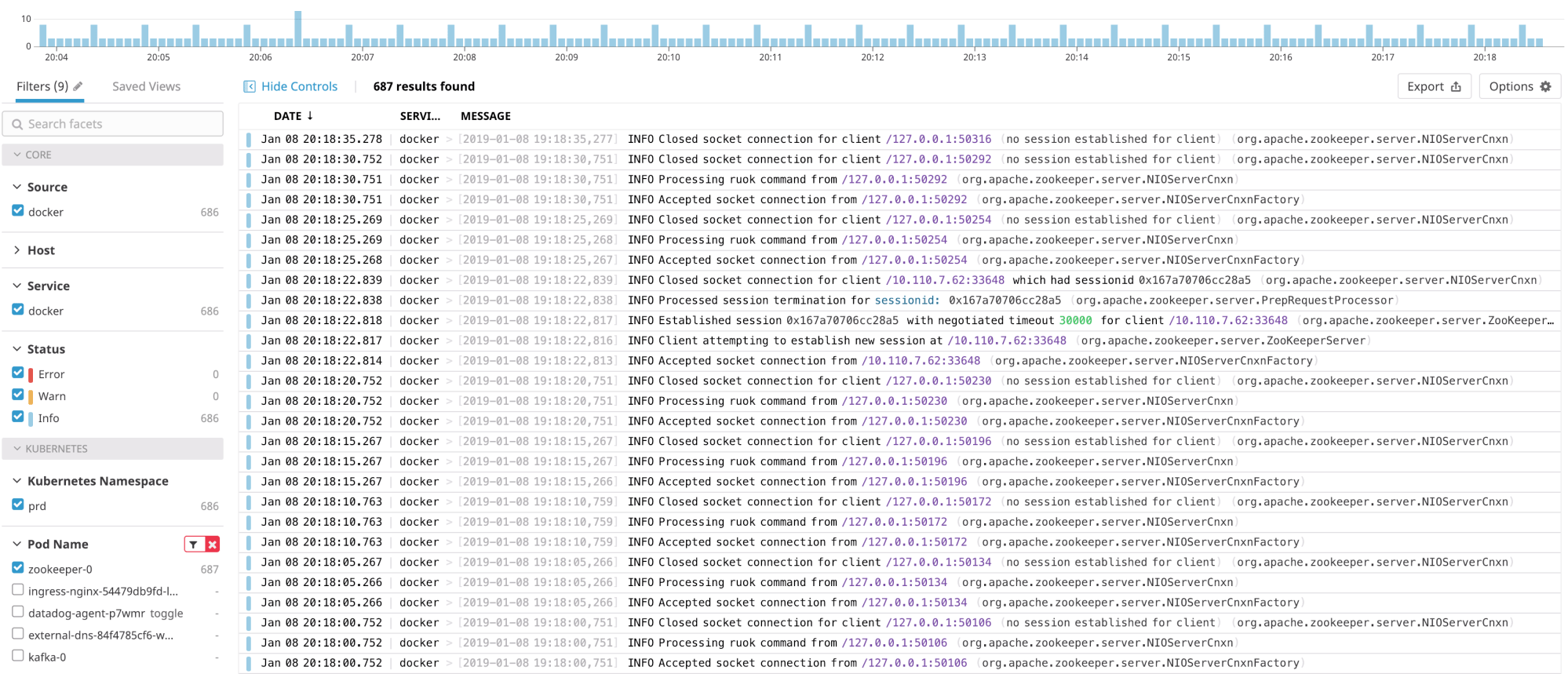
Datadog Logs is a little bit less mature than the monitoring part, but it’s still one of our favourite logging solutions. It’s relatively cheap and the same agent can be used for both monitoring and logging.
Monitors – which are used to trigger alerts – can be created from the log data and log data can also be visualized in dashboards. You can see the logs by navigating here and filter them by container, namespace or pod name. It’s also possible to filter your logs by label, which you can add to your Deployment, StatefulSet, …
As you’ve noticed, Datadog already provides a lot of data by default. However, extra metric collection and dashboards can easily be added by adding integrations. Datadog claims they have more than 200 integrations you can enable.
Here’s a list of integrations we usually enable on our clusters:
Installing integrations is usually a very straightforward process. Some of them can be enabled with one click, others require some extra configuration. Let’s take a deeper look at setting up some of the above integrations.
This integration should be configured both on the Datadog and AWS side. First, in AWS, we need to create a IAM Policy and a AssumeRolePolicy to allow access from Datadog to our AWS account.
The content for the IAM Policy can be found here. Attach both Policies to an IAM Role called DatadogAWSIntegrationRole. Go to your Datadog account setting and press on the “+Available” button under the AWS integration. Go to the configuration tab, replace the variable ${var.Datadog_aws_external_id} in the policy above with the value of AWS External ID.
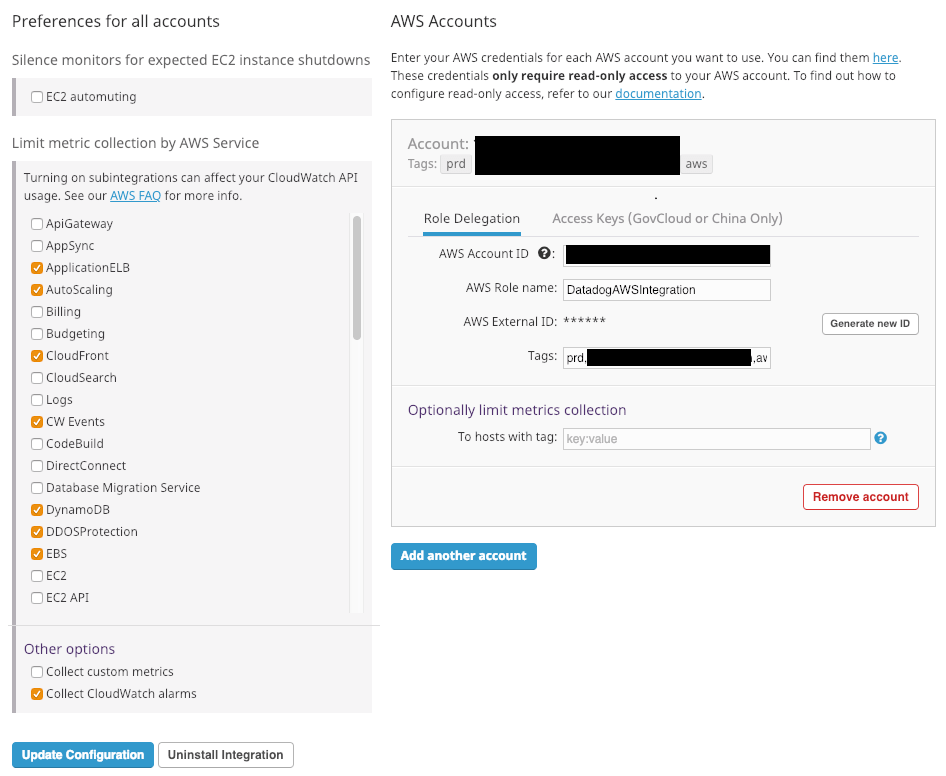
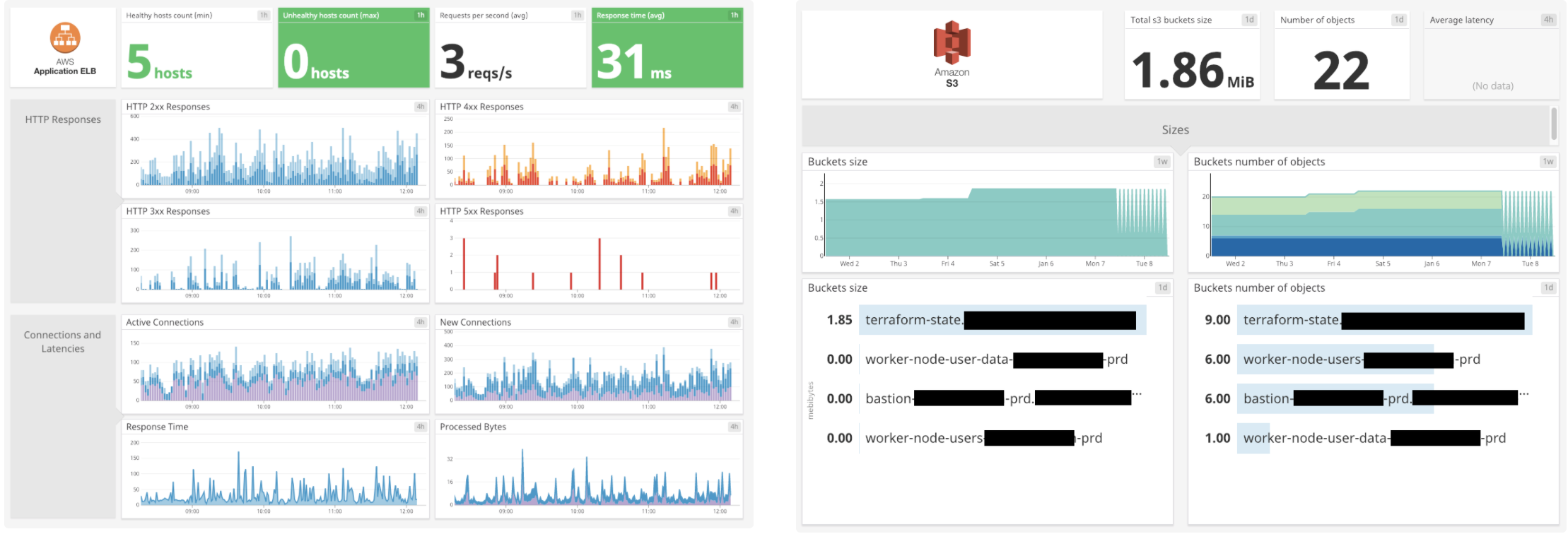
Add the AWS account number and for the role use DatadogAWSIntegrationRole as created above. Optionally, you can add tags which will be added to all metric gathered by this integration. On the left, limit the selection to the AWS services you use. Lastly, save the integration and your AWS integration (and integration for the enabled AWS Services) will be shown under “Installed”.
When you go to your dashboard list, you’ll see some new interesting dashboards with new metrics you can use to create new monitors with, such as:
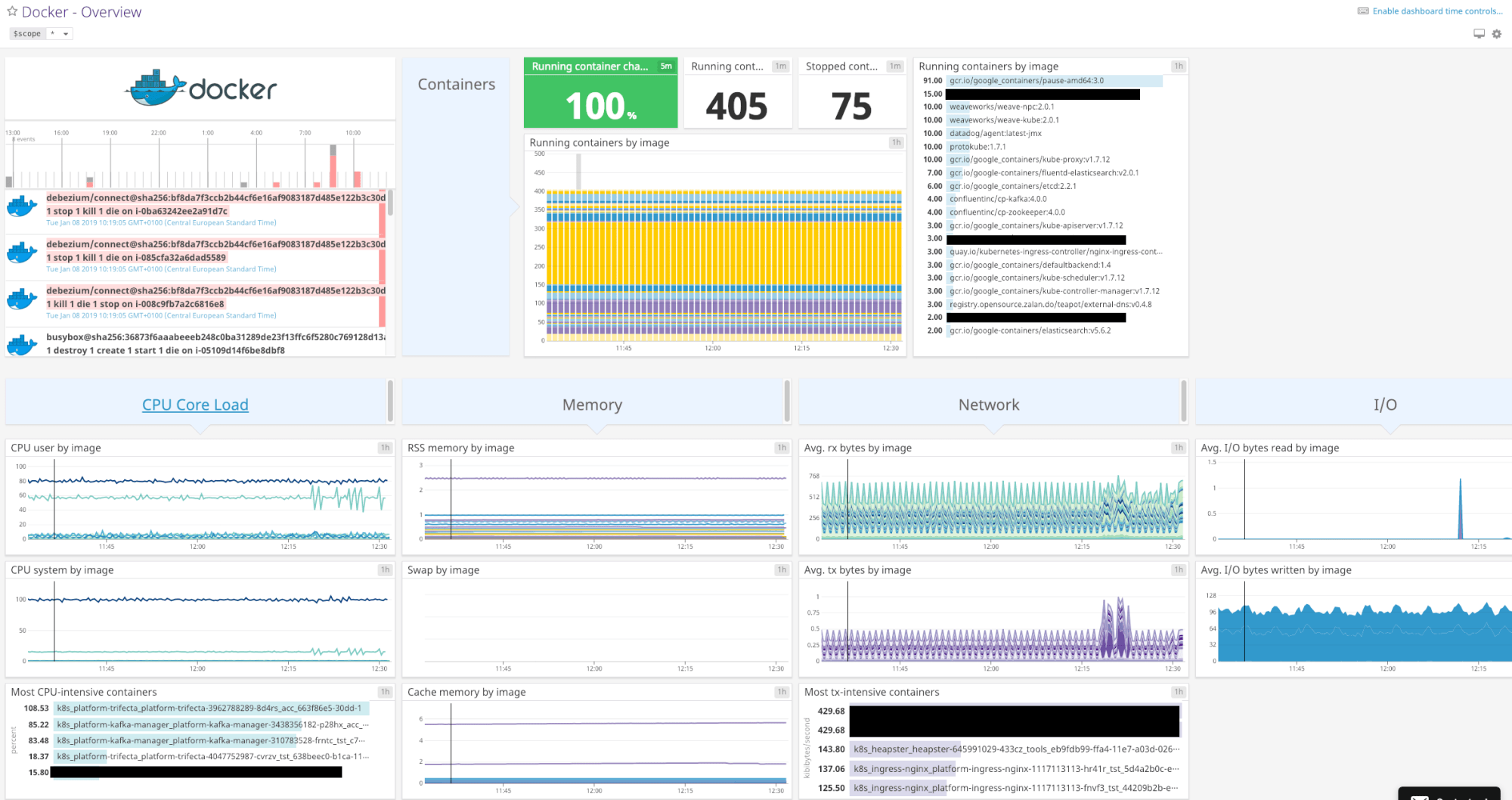
Enabling the Docker integration is as easy as pressing the “+Available” button. A “Docker – Overview” dashboard is available as soon as you enable the integration.
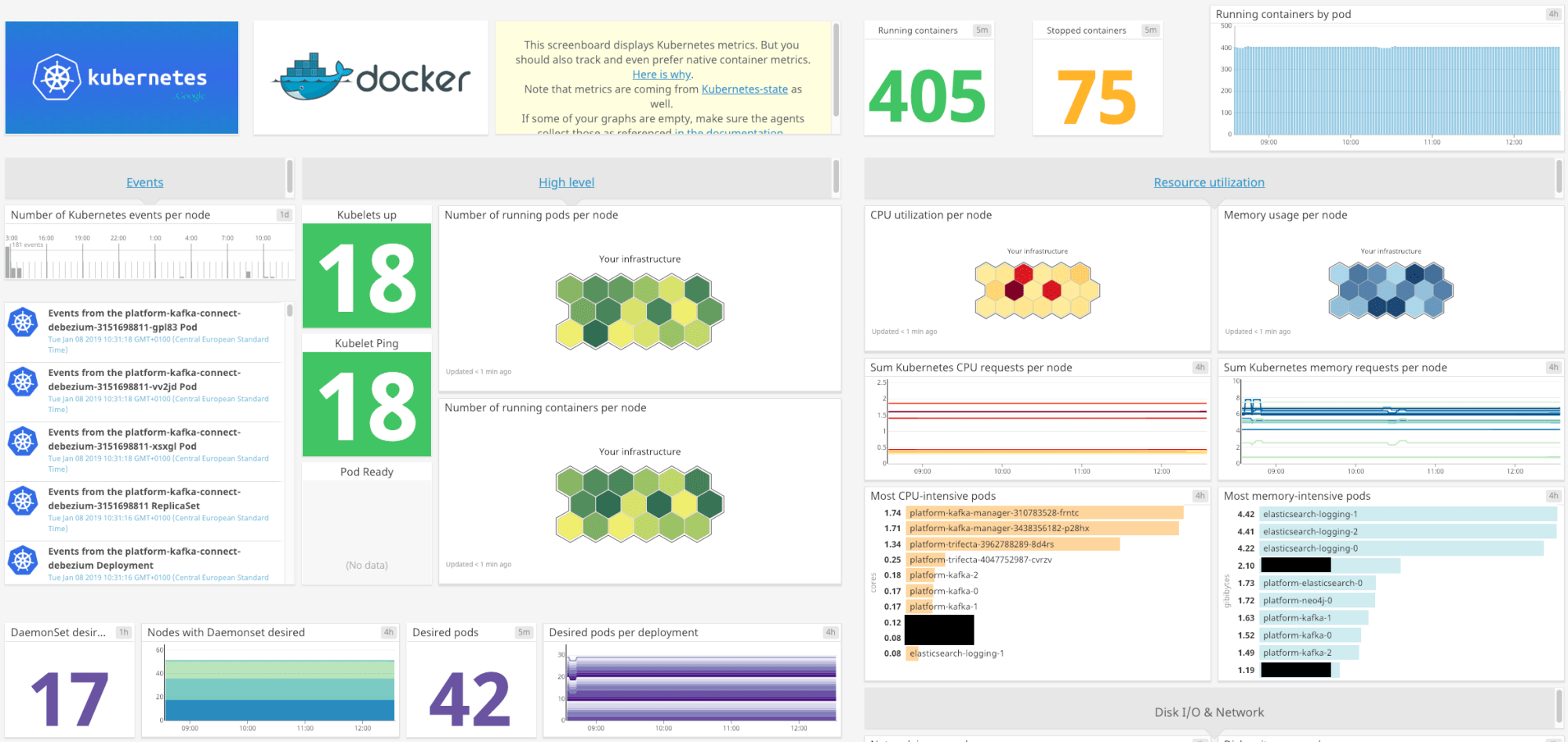
Just like the Docker integration above, enabling the Kubernetes integration is as easy as pressing the “+Available” button, with a “Kubernetes – Overview” dashboard available as soon as you enable the integration.
The goal of this article was to show you how Datadog can become your most indispensable tools in your monitoring and logging infrastructure. Setup is pretty easy and there is so much information that can be collected and visualized effectively.
If you can create a good set of monitors so Datadog alerts in case of degradation or increased error rates, most incidents can be solved even before they become actual problems. You can script the creation of these monitors using the Datadog API, reducing the setup time of your monitoring and alerting framework drastically.
Do you want more information, or could you use some help setting up your own EKS cluster with Datadog monitoring? Don’t hesitate to contact us!

ACA Group joined over 2,000 attendees at SUSECON 2026, and one thing was clear: SUSE is accelerating its momentum in Europe, especially around digital sovereignty, AI, and edge computing.
Read more
A few years ago, AI felt like a fantastic gimmick. Last week in Amsterdam, that illusion fell apart completely. I've been part of the circus that the IT sector sometimes is for many years now. Just when you think you've seen everything, reality catch
Read more

AWS Quick is Amazon's answer to a problem nearly every business user knows: AI tools that can answer questions, but can't take action. AWS Quick is different. It's an agentic AI platform built to automate multi-step workflows across your entire tech
Read moreGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!

{kind=link}
{kind=link}
{kind=link}