.svg?width=174&auto=compress,webp&upscale=true)
.svg?width=139&auto=compress,webp&upscale=true)

6 MAY 2025
Reading time 4 min
Stijn Schutyser

At ACA, we live and breathe Kubernetes. We set up new projects with this popular container orchestration system by default, and we’re also migrating existing customers to Kubernetes. As a result, the amount of Kubernetes clusters the ACA team manages, is growing rapidly! We’ve had to change our setup multiple times to accommodate for more customers, more clusters, more load, less maintenance and so on.
In 2016, we had a lot of projects that were running in Docker containers. At that point in time, our Docker containers were either running in Amazon ECS or on Amazon EC2 Virtual Machines running the Docker daemon. Unfortunately, this setup required a lot of maintenance. We needed a tool that would give us a reliable way to run these containers in production. We longed for an orchestrator that would provide us high availability, automatic cleanup of old resources, automatic container scheduling and so much more.
Kubernetes proved to be the perfect candidate for a container orchestration tool. It could reliably run containers in production and reduce the amount of maintenance required for our setup.
Agile as we are, we proposed the idea for a Kubernetes setup for one of our next projects. The customer saw the potential of our new approach and agreed to be part of the revolution. At the beginning of 2017, we created our first very own Kubernetes cluster. At this stage, there were only two certainties: we wanted to run Kubernetes and it would run on AWS. Apart from that, there were still a lot of questions and challenges.

We’ve learned that in the end, the hardest task was not the cluster setup. Instead, creating a new mindset within ACA Group to accept this new approach, and involving the development teams in our next-gen Kubernetes setup proved to be the harder task at hand. Apart from getting to know the product ourselves and getting other teams involved as well, we also had some other tasks that required our attention:
Getting used to this new way of doing things in combination with other tasks, like setting up good monitoring, having a centralized logging setup and deploying our applications in a consistent and maintainable way, proved to be quite challenging. Luckily, we were able to conquer these challenges and about half a year after we’d created our first Kubernetes cluster, our first production cluster went live (August 2017).

These were the core components of our toolset anno 2017:
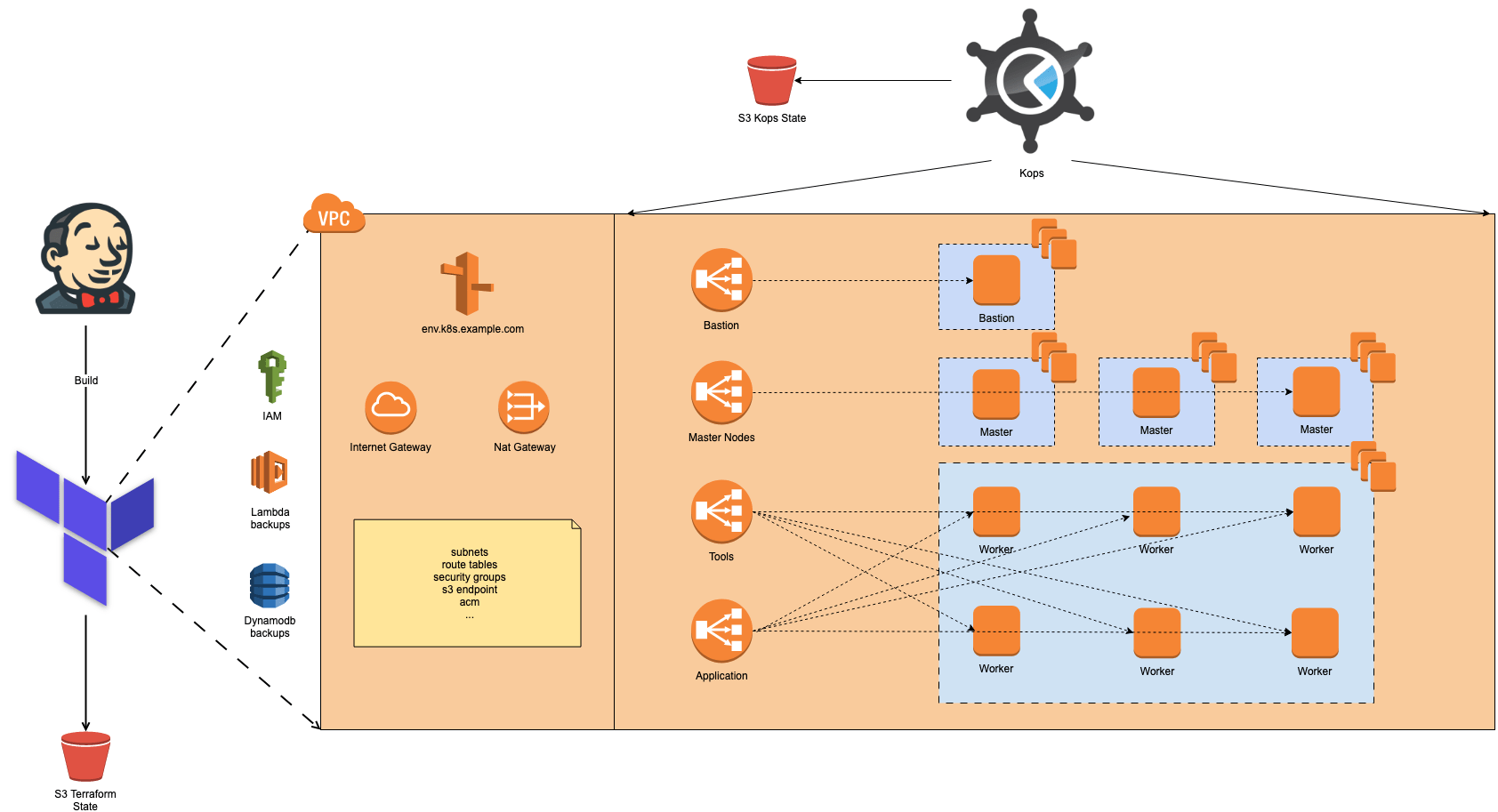
Once we had completed our first setup, it became easier to use the same topology and we continued implementing this setup for other customers. Through our infrastructure-as-code approach (Terraform) in combination with a Kubernetes cluster management tool (Kops), the effort to create new clusters was relatively low.

However, after a while, we started to notice some possible risks related to this setup. The amount of work required for the setup and the impact of updates or upgrades on our Kubernetes stack was too large. At the same time, the number of customers that wanted their very own Kubernetes cluster was growing. So, we needed to make some changes to reduce maintenance effort on the Kubernetes part of this setup to keep things manageable for ourselves.
At this point the Kubernetes service from AWS (Amazon EKS) became generally available. We were able to move all things that are managed by Kops to our Terraform code, making things a lot less complex. As an extra benefit, the Kubernetes master nodes are now managed by EKS. This means we now have less nodes to manage and EKS also provides us cluster upgrades with a touch of the button.

Apart from reducing the workloads on our Kubernetes management plane, we’ve also reduced the number of components within our cluster. In the previous setup we were using an EFK (ElasticSearch, Fluentd and Kibana) stack for our logging infrastructure. For our monitoring, we were using a combination of InfluxDB, Grafana, Heapster and Librato. These tools gave us a lot of flexibility but required a lot of maintenance effort, since they all ran within the cluster. We’ve replaced them all with Datadog agent, reducing our maintenance workloads drastically.
Furthermore, because of the migration to Amazon EKS and the reduction in the number of components running within the Kubernetes cluster, we were able to reduce the cost and availability impact of our cluster upgrades. With the current stack, using Datadog and Amazon EKS, we can upgrade a Kubernetes cluster within an hour. If we were to use the previous stack, it would take us about 10 hours on average.
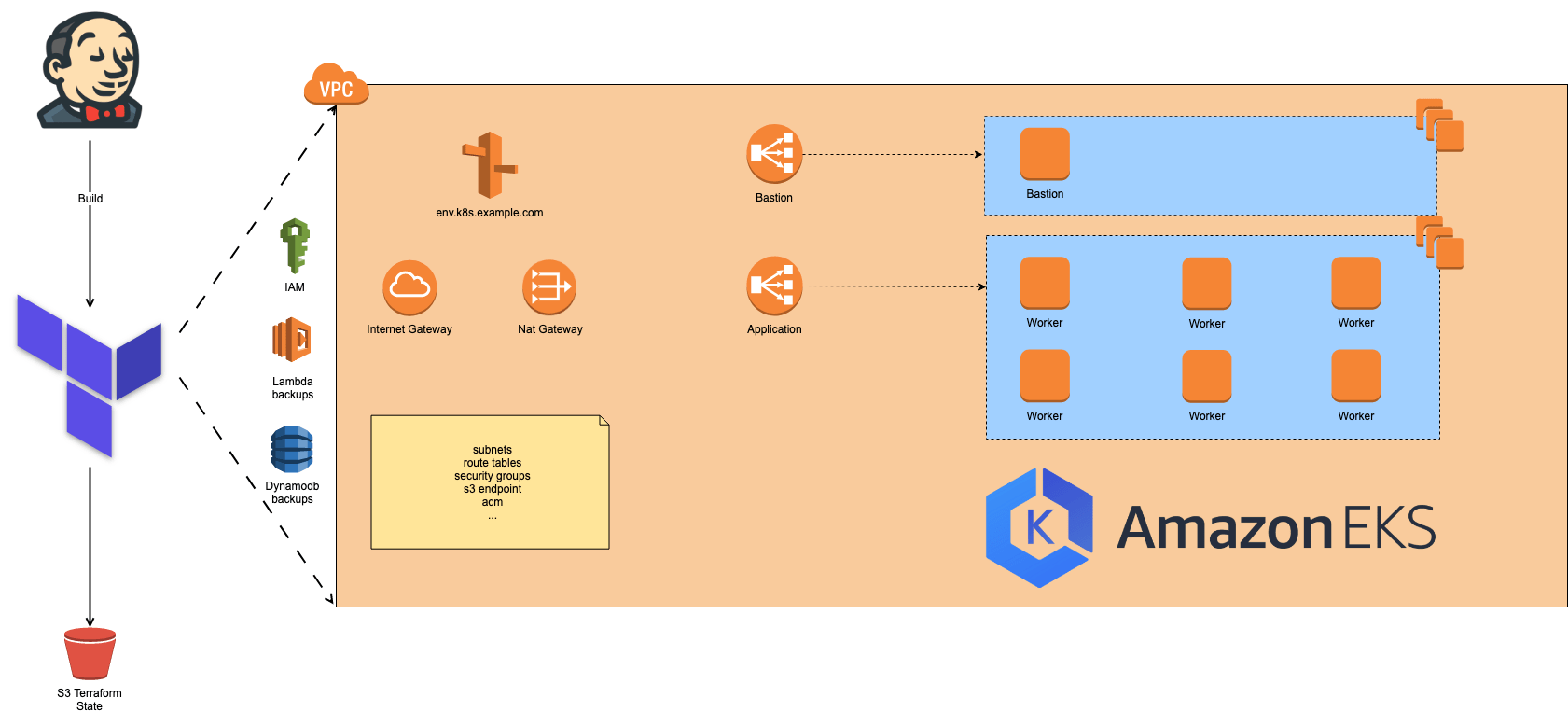
We currently have 16 Kubernetes clusters up and running, all running the latest available EKS version. Right now, we want to spread our love for Kubernetes wherever we can.
Multiple project teams within ACA Group are now using Kubernetes, so we are organizing workshops to help them get up to speed with the technology quickly. At the same time, we also try to catch up with the latest additions to this rapidly changing platform. That’s why we’ve attended the Kubecon conference in Barcelona and shared our opinions in our Kubecon Afterglow event.
Even though we are very happy with our current Kubernetes setup, we believe there’s always room for improvement. During our Kubecon Afterglow event, we’ve had some interesting discussions with other Kubernetes enthusiasts. These discussions helped us defining our next steps, bringing our Kubernetes setup to an even higher level. Some things we’d like to improve in the near future:
Of course, these are just a few focus points. We’ll implement many new features and improvements whenever they are released!
Contact us at cloud@aca-it.be and we will help you out!

ACA Group joined over 2,000 attendees at SUSECON 2026, and one thing was clear: SUSE is accelerating its momentum in Europe, especially around digital sovereignty, AI, and edge computing.
Read more
A few years ago, AI felt like a fantastic gimmick. Last week in Amsterdam, that illusion fell apart completely. I've been part of the circus that the IT sector sometimes is for many years now. Just when you think you've seen everything, reality catch
Read more

AWS Quick is Amazon's answer to a problem nearly every business user knows: AI tools that can answer questions, but can't take action. AWS Quick is different. It's an agentic AI platform built to automate multi-step workflows across your entire tech
Read moreGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
