


Dataproduct analyse: hoe begin ik eraan?
In de wereld van data mesh staan dataproducten centraal. Maar, wat is een dataproduct nu precies en hoe pak je de functionele analyse van zo'n dataproduct best aan? Je ontdekt het in deze blogpost.
Dataproduct?
De basisidee van een data mesh bestaat uit 2 luiken:
- Het vergroten van de toegankelijkheid, de beschikbaarheid en de bruikbaarheid van gegevens voor zakelijke gebruikers.
- Het verminderen van afhankelijkheden tussen datateams.
Hierbij baseren we ons op de principes van domein-georiënteerd ownership, federated computational governance, self-service dataplatforms en product thinking. Vooral dit laatste is belangrijk bij het begrip en de ontwikkeling van een dataproduct. We willen gegevens namelijk beschouwen en vormgeven als een herbruikbaar product, zodat het op verschillende manieren kan ingezet worden, waarbij de waarde ervan wordt gemaximaliseerd.
Een dataproduct is een logische eenheid die alle componenten bevat om domeingegevens te verwerken en op te slaan voor verschillende use cases zoals data analytics, en deze beschikbaar maakt voor andere teams via ‘outputpoorten
— Majchrzak Jacek, Author bij Data Mesh in Action



Een dataproduct heeft ook zijn eigen onafhankelijke levenscyclus en beheersstructuren. Eigenlijk kan je een dataproduct vergelijken met een microservice, maar dan voor analytische gegevens.
Dataproducten maken via inputpoorten verbinding met bronnen, zoals operationele systemen, dataplatformen of andere dataproducten, en voeren bepaalde operaties op data uit (vb. transformaties, berekeningen, anoniem maken van data, enz.).
Bij het uitwerken van een dataproduct komen heel wat aspecten aan bod: het bepalen van input- en output poorten, data cleaning, transformaties, mapping van velden, GDRP-regelgeving, enz. Daarom is een grondige analyse heel belangrijk.
Maar, hoe begin je aan zo’n dataproduct analyse?
Stappenplan voor dataproduct analyse
Een gestructureerde analyse-aanpak garandeert de beste resultaten. Voor dataproducten doen we daarom beroep op het Data Product Canvas dat we koppelen aan een handige checklist.
Het canvas is een visuele voorstelling die op een eenvoudige manier de verschillende cruciale onderdelen van je dataproduct analyse weergeeft. Met de checklist ben je zeker dat je niets over het hoofd ziet.
Data Product Canvas
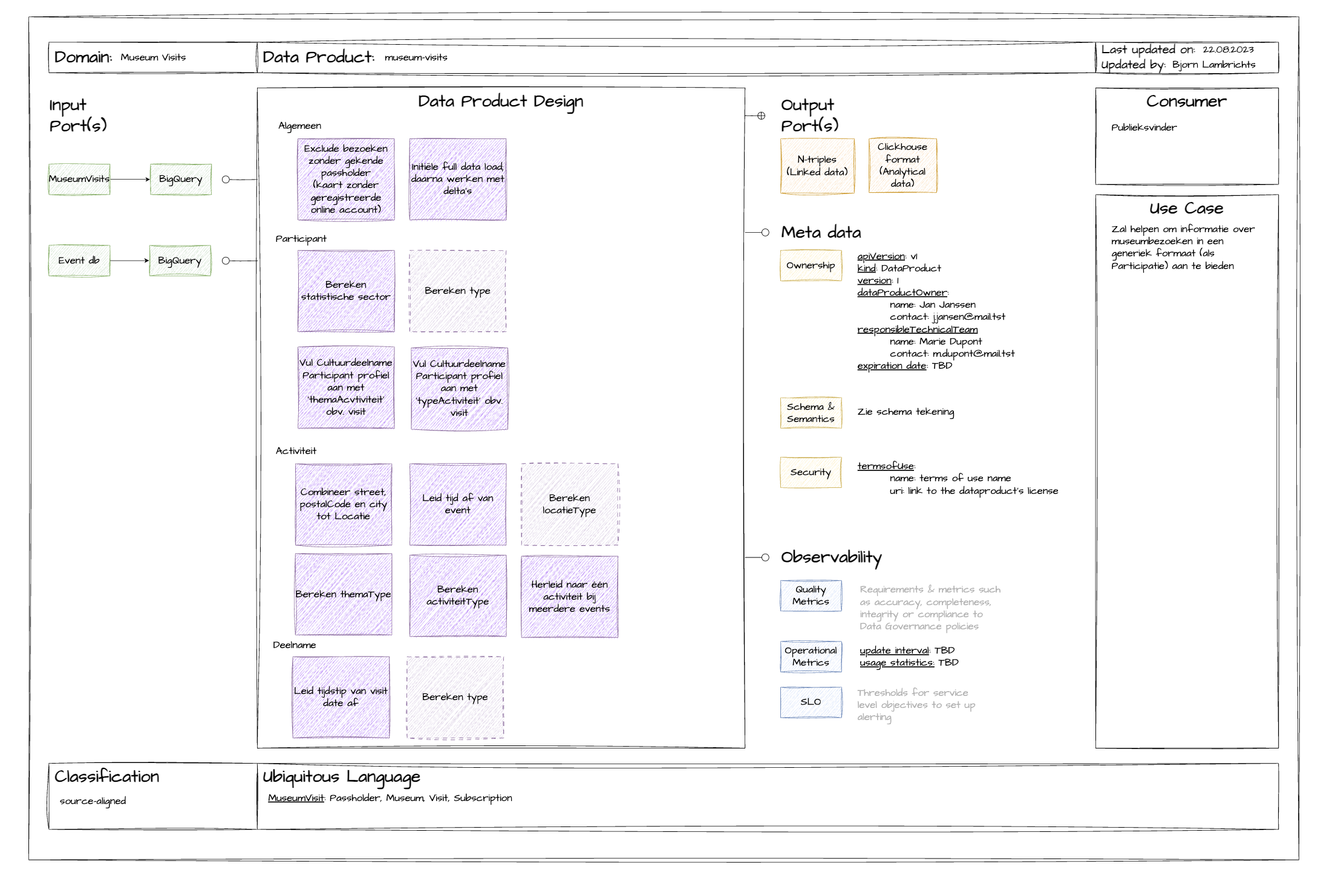
Met het Data Product Canvas zorgen we ervoor dat er in een organisatie een eenduidig proces voor het ontwerpen van een dataproduct bestaat. Het canvas geeft op een beknopte manier weer met welke onderdelen je tijdens je analyse rekening moet houden.
Aan de hand van dit canvas kan je de verschillende stakeholders van het dataproduct ondervragen. Zo kom je samen tot het gewenste resultaat.
Op basis van onze ervaring met dit canvas raden we aan om het in een specifieke volgorde in te vullen. Je start best met de specificatie van het dataproduct. Zo breng je direct alle beschrijvende gegevens in kaart, zorg je ervoor dat alle belanghebbenden bekend zijn en verduidelijk je het doel van het dataproduct.
Vervolgens ga je verder met de outputpoorten, omdat de stakeholders van het dataproduct vaak goed weten welke data ze nodig hebben. Je kan ze vergelijken met eindgebruikers van een applicatie die baat hebben bij een goede gebruikerservaring.
Daarna neem je de inputpoorten onder handen. Op basis van de feedback van de dataconsumenten, ga je zoeken welke inputbronnen de nodige data kunnen aanleveren.
Tenslotte, sluit je af met het ontwerp van het dataproduct. In deze fase komen input en output samen en probeer je een logische manier te bedenken om input om te zetten in de gewenste output.
De checklist
1. Dataproduct specificatie
Zorg ervoor dat je alle beschrijvende gegevens van je dataproduct verzamelt. Dit zijn o.a.:
- Naam van het domein
- Naam van het dataproduct
- Ownership: wie beheert het dataproduct: contactgegevens van de dataproduct owner, contactgegevens van het technisch team, vervaldatum van het dataproduct
- Security: Dataproduct security is essentieel: het bepaalt hoe en door wie het dataproduct gebruikt mag worden. Je geeft hier aan welke licentie (‘terms of use’) aan het dataproduct gekoppeld is.
- Update frequentie: De frequentie bepaalt hoe dikwijls het dataproduct bijgewerkt wordt. Je geeft best ook aan hoe de bijwerking gebeurt (bv. full load, incrementeel, …)
- Dataconsumenten: De dataconsumenten van een dataproduct zijn de applicaties of andere dataproducten die de output van je dataproduct zullen gebruiken.
- Use cases: Met use cases beschrijf je het doel van je dataproduct. Ze geven meer informatie over de noden en de bestaansreden van het dataproduct.
2. Terminologie
In veel bedrijven en projecten ontstaat er vaak verwarring over de betekenis van bepaalde concepten, begrippen of woorden. Ubiquitous language — een principe uit Domain Driven Design — probeert hier een oplossing voor te bieden door te streven naar een vocabulaire die door alle stakeholders gedeeld en eenduidig begrepen wordt.
Om spraakverwarring en interpretatieverschillen te vermijden bij het ontwikkelen en analyseren van een dataproduct, moet je zeker aandacht hebben voor ubiquitous language. Neem dus zeker de definities van termen op die in de context van het dataproduct van toepassing zijn. Verwijzingen naar andere glossaries, wiki’s, … kunnen natuurlijk ook.
3. Outputpoorten
Outputpoorten bepalen het formaat en het protocol waarin data ter beschikking van je dataconsumenten gesteld wordt. Bespreek met je dataconsumenten (en andere stakeholders) in welk formaat ze data wensen te consumeren. Voorbeelden van output port types zijn analytical data, blob stores, Linked Data, enz..
4. Inputpoorten
Inputpoorten geven aan in welk formaat en op welke manier brondata gelezen kan worden. Door contact op te nemen met de owners van je bronsystemen (of brondataproducten) kan je achterhalen welke mogelijkheden er zijn.
Vermeld zeker over welk type inputpoort het gaat (bv. API, databank, file, …) en noteer ook uit welke tabellen van het bronsysteem de nodige data gehaald kan worden.
Het is overigens heel handig om in deze stap een visuele voorstelling van het domein van het bronsysteem toe te voegen.
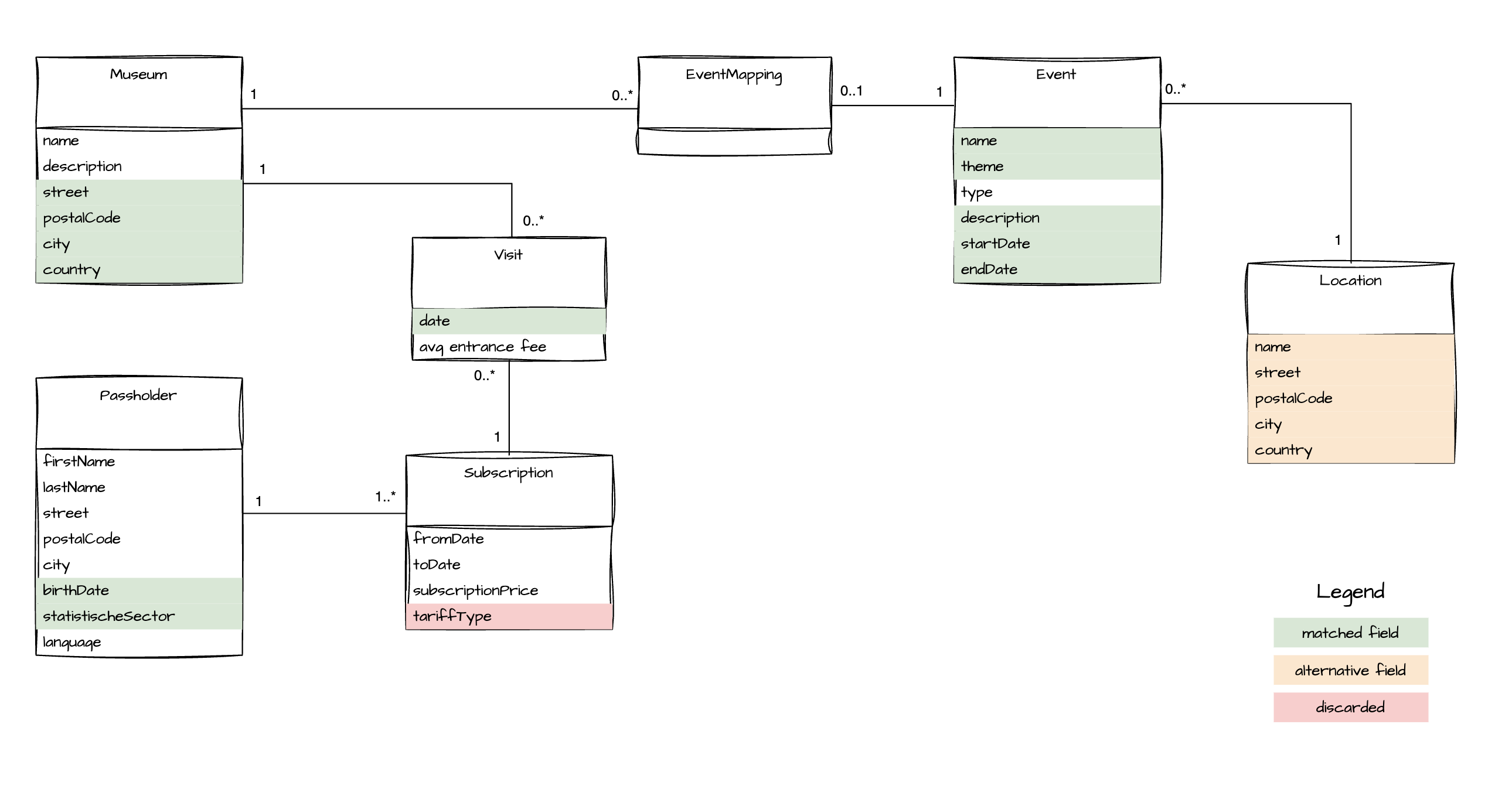
5. Dataproduct Design
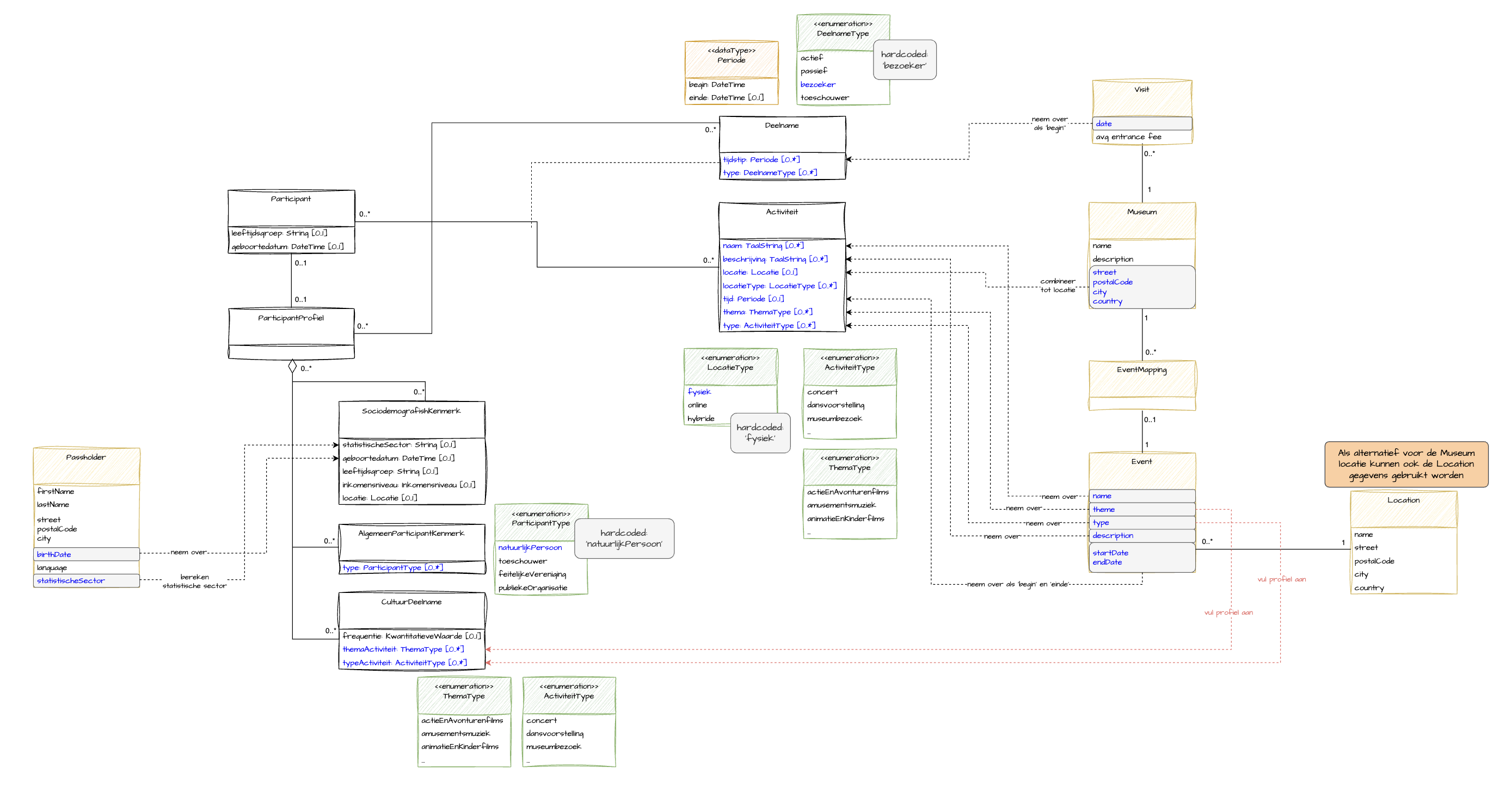
Dit is de laatste en misschien wel de belangrijkste stap in de analyse van een dataproduct. In deze stap ga je nadenken over de logica van transformaties binnen het dataproduct.
Denk hierbij aan:
- Identificatie van gewenste input data/velden
- Identificatie van gewenste output data/velden
- Beperkingen van data input (bv. niet alle informatie is in alle gevallen beschikbaar)
- Data cleaning
- Datatransformatie(s)
- Mapping van inputvelden
- Mapping naar outputvelden
- Dataverrijking
- Data ‘anoniem’ maken (bv. ihkv. GDPR-wetgeving)
- Berekeningen op data
In onderstaand praktisch voorbeeld tackelen we een aantal van bovenstaande topics. Zo zie je welke bronvelden gemapt worden en hoe je er best mee omgaat. Daarnaast worden bepaalde velden berekend op basis van inputdata (bv. locatie).
Tot slot
Bij het analyseren van dataproducten komt heel wat kijken. Maar, met een goed gestructureerde aanpak, een visueel framework en een eenvoudige checklist kan je deze klus vlot tot een goed einde brengen.
💡 Wil je meer te weten komen over data mesh of de ACA methodologie? Vul het formulier dan in op deze pagina!





