


Applying Data Mesh principles to an IoT data architecture
In a previous blog post, we described an Internet of Things (IoT) case in which the IoT data became part of an enterprise-grade data platform. This allows you to combine the IoT data with other datasets you may have available in your enterprise. The challenge is to design your data platform so that it scales with the number of datasets, provides the necessary business agility, avoids ending up with an unmaintainable monolithic data platform, and avoids making only one team responsible as a bottleneck for getting things done. This blog post shows how a data mesh approach helps by explaining what it is, its principles and applying it to the IoT data case as an example.
The evolution towards data mesh
Let's start with explaining what 'data mesh' is and the principles it aims for. We'll begin by looking at how the operational space evolved over the last decade.
From monolithic architectures towards micro-services
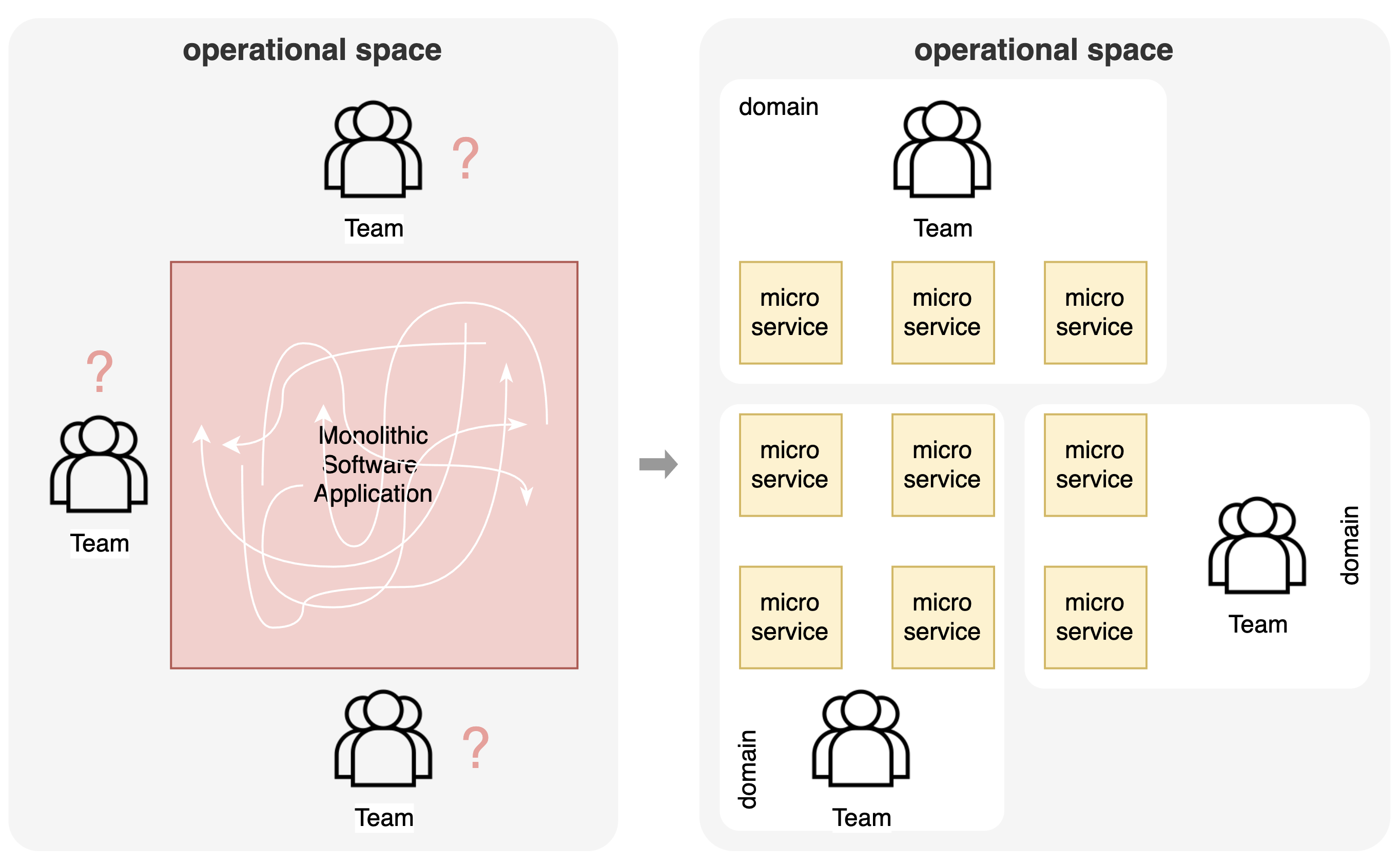
In the past, software applications were often built as big monolithic systems with their typical problems. A monolithic architecture typically evolves towards a 'big ball of mud' which makes it hard to maintain, to change things and to provide the necessary business agility a company needs. At the same time, when scaling towards multiple teams within a company, such an architecture does not provide enough flexibility and makes it unclear which part of the software is owned by which team. As a solution, the operational space went through an evolution towards a microservices architecture. Using techniques from domain driven design, a decomposition is designed based on business domains and into software services. The challenge is to find the right granularity to enable the desired business agility in a composable architecture. This decomposition also enables scaling to multiple teams. Each team is responsible for a business domain, which implies that each microservice is clearly owned by one team.
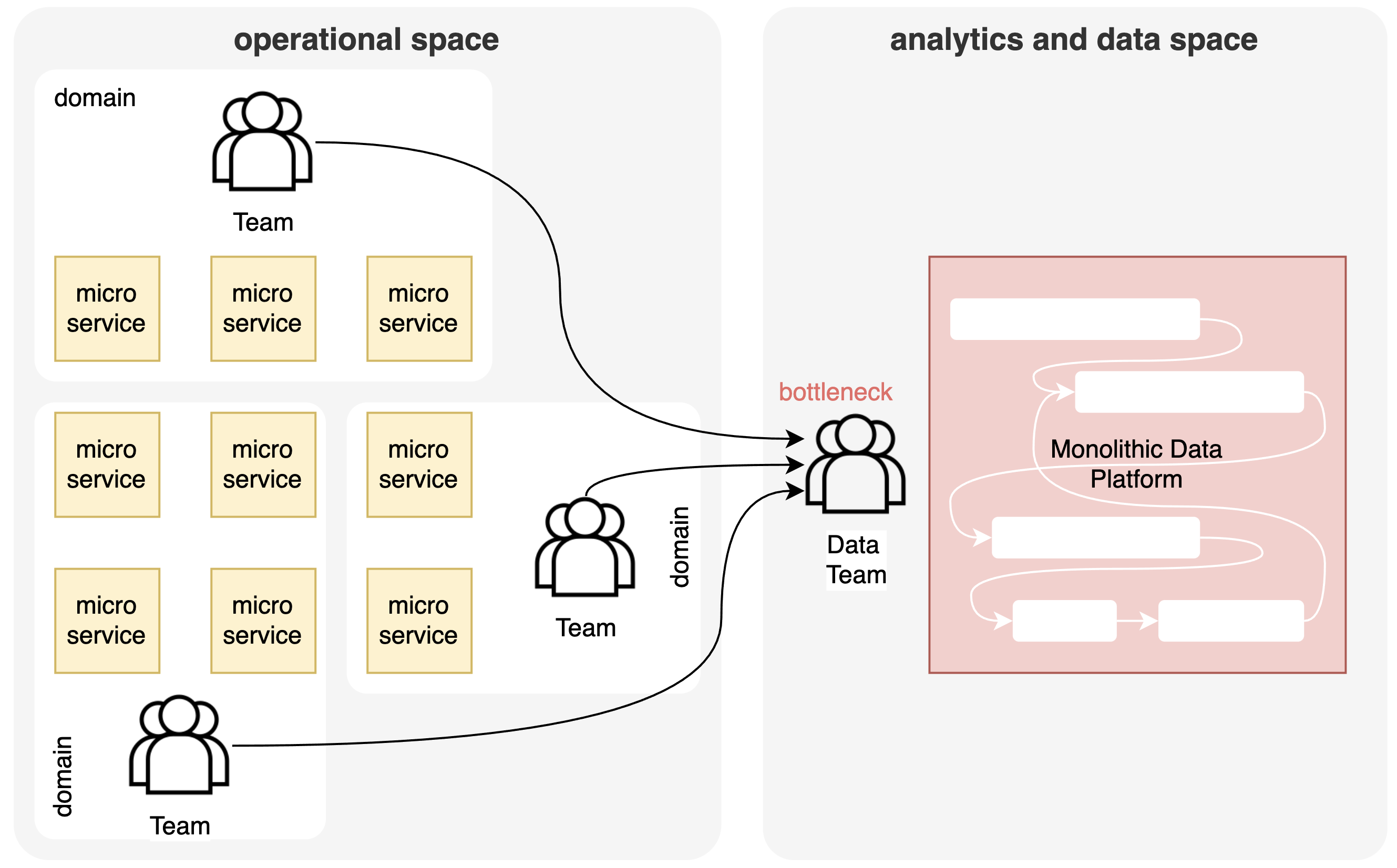
What we see today is a similar trend in the analytics and data space. If we put the analytics and data space next to the operational space, we see again a monolithic structure in the form of data lakes and data warehouses owned by a separate team of data engineers. So even if there is a clear decomposition in the operational space, there is still a monolith in the analytics space, resulting in similar problems. Data pipelines tend to grow over time into a unmaintainable mess of chained pipelines with long execution times, high storage requirements, all-or-nothing upgrades with global downtime, etc. Ownership to structure data and make it usable is assigned to a central team of data engineers that become a bottleneck when the amount of datasets scales and when the frequency of changes increases. This again becomes problematic for enabling the business agility a company needs.
Data products for more structure and ownership
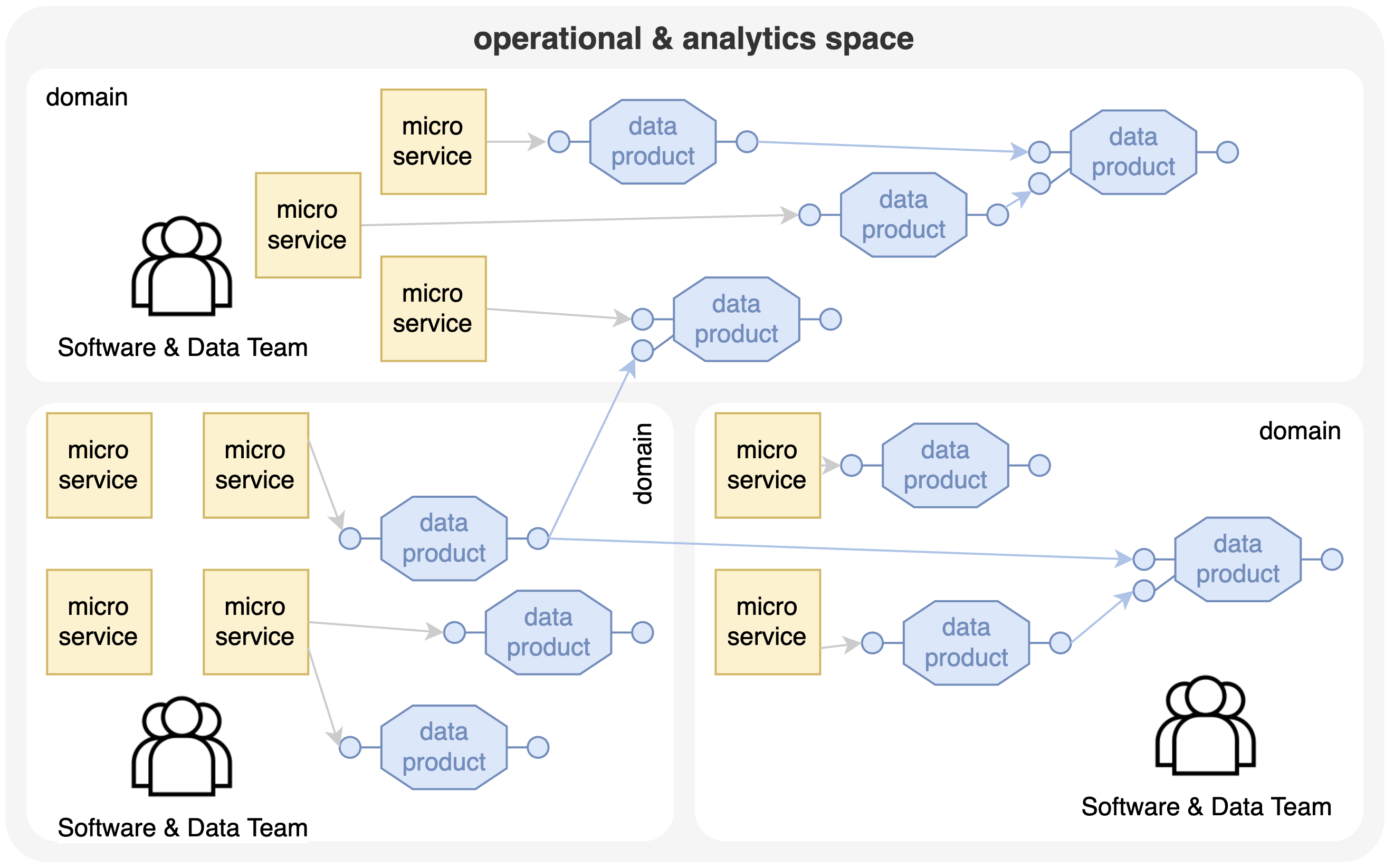
For the analytics & data space, then, we also need to find a suitable decomposition that aligns with the business domains for which business agility is desired. This decomposition is called a 'data product' which consumes data from operational services and other data products and produces data with a clear API or data contract. These data products are owned by the respective business domains, together with microservices for that domain. A cross-functional team of software engineers and data engineers is responsible for building, maintaining and evolving a domain. As such, a network of interconnected data products called a 'data mesh' appears. Note that there are still connections between services and between data products that can result in advanced networks, but the biggest difference is that these connections follow clear APIs or contracts defined by components that clearly structure the IT landscape and the ownership of it.
The concept of data mesh was introduced by Zhamak Dehgani. You can refer to her recently published book for all the details. As a recap, there are four principles which a data mesh journey aims to achieve. These principles complement each other and each addresses new challenges that may arise from others:
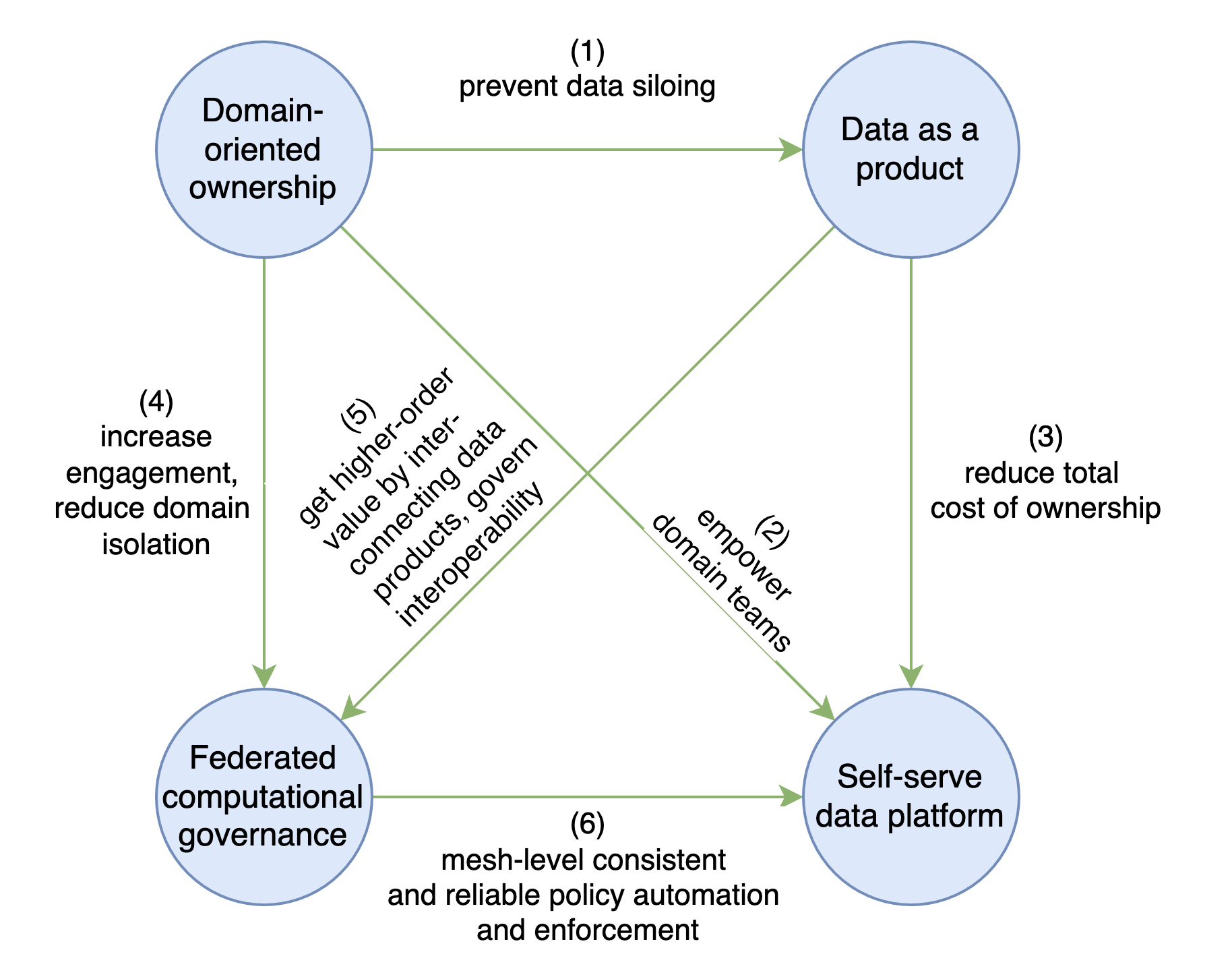
- Domain-oriented ownership: decentralize the ownership of analytical data to business domains closest to the data — either the source of the data or its main consumers.
- Data as a product: avoid isolation in domain silos by stimulating sharing data as a product. Apply techniques from product thinking and product ownership to design a new autonomously evolvable and deployable architectural unit with a data contract API that is optimized for usability by data users, data analysts and data scientists.
- Self-serve data platform: reduce total cost of ownership and remove friction from the journey of data sharing, access, and consumption with a self-service platform that manages the full life cycle of individual data products (build, deploy and maintain), and provides mesh-level capabilities to discover available data products and increased observability through knowledge graphs, data lineage, and data quality/usage metrics across the mesh.
- Federated computational governance: instead of central governance, increase domain engagement by enabling federated decision-making and accountability, with a team composed of domain representatives, data platform, and subject-matter experts (e.g. legal, compliance, security, etc). This model balances the autonomy and agility of domains, with the global interoperability of the mesh. This interoperability enables getting higher-order value by making it easy to interconnect data products. The 'computational' aspect refers to automating the governance policies for every data product and enforce them through reliable self-service platform capabilities.
Data product as new architectural quantum
From the book 'Building Evolutionary Architectures', an architectural quantum is an independently deployable component with high functional cohesion, which includes all the structural elements required for it to function properly. As such, the 'data product' in our data mesh is a new architectural quantum. It can be visualized as follows:



A data product encapsulates these structural elements required for providing the data as a product:
- 1 or more input ports which take in data from source systems or other data products
- 1 or more output ports which serve the data in (multiple) format(s) and through (multiple) protocol(s) following a data contract API. Note that 'API' is not limited to a typical REST API, it refers to an agreed upon technology, format and protocol to exchange data which can be a REST API, but could also be an SQL database connection, an S3 storage, etc. However, it should never be the internal model of an operational system, but an explicitly designed external model/table/schema that serves as an API.
- the data storage needed internally or to serve the data in an output port
- the actual code that applies the transformation logic from input ports to output ports
- provided governance policies that are enforced within the data product
- metadata that makes the data product discoverable and self-documenting (discovery port)
- monitoring (i.e. metrics) and management of the data product (control port)
Using this data product and its different aspects allows to reason about and design a suitable decomposition of a data platform.
IoT data as a simple use case
Let's take an example use case to illustrate how a mesh of data products can already help as a useful design paradigm. The use case concerns itself with using Internet of Things (IoT) data together with other enterprise data to provide valuable insights into well-being and health of employees in the workplace and children in schools. For a full description of the use case, we refer to our previous blog post entitled 'Using IoT and digital canaries to improve health'.
In short, there are 3 operational systems involved:
- an IoT platform reading telemetry data from the IoT devices using Google Cloud IoT Core and Google Cloud Pub/Sub
- a Google sheet in which metadata about the IoT devices is captured (location, building, floor, outside co2 level, ...)
- a Google sheet in which a logbook is kept of the actions that are taken to improve the health of the working environment, and thus improve the values sensed by the IoT devices
All these systems belong to the IoT domain and are owned by one team: the IoT team.



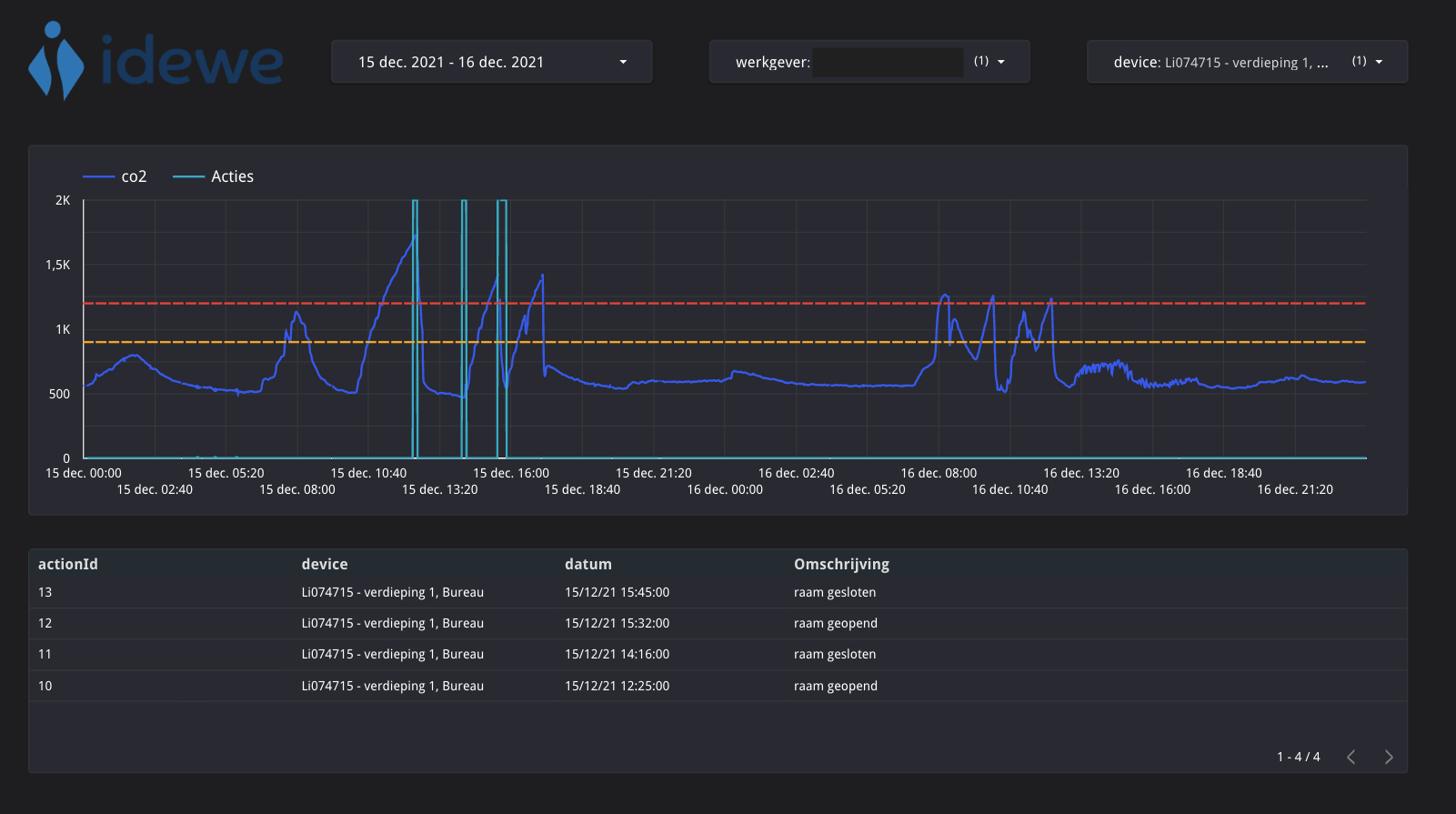
For analytics and reporting Google Data Studio is used and owned by the data analytics team. An example of a resulting dashboard is shown below. In what follows, we show how a mesh of data products emerged from designing the data platform. The resulting data mesh gets the data from the operational systems into the desired dashboard.


Evolution of the IoT data mesh
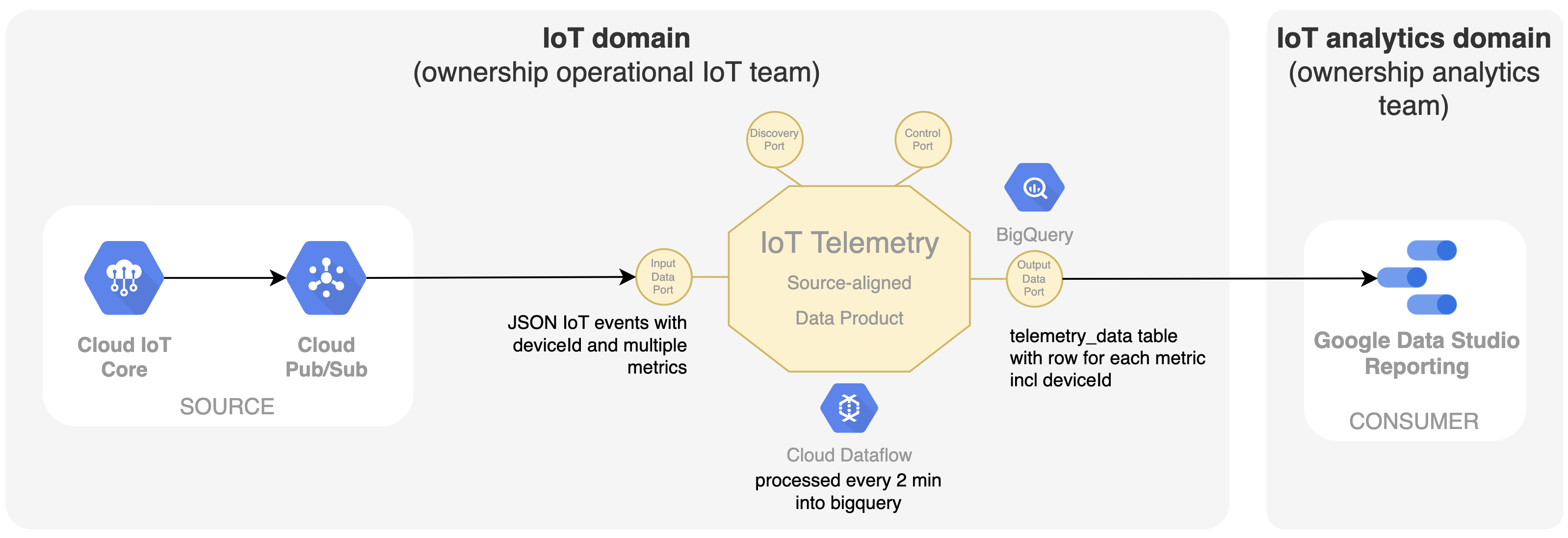
In IoT, the core data is of course the telemetry data coming from the IoT devices themselves. The team owning this IoT system is now also responsible to share this time series data as a data product on the data mesh platform. Our first data product called 'IoT Telemetry' is introduced, which takes the IoT events containing multiple metrics from Google Pub/Sub and transforms them using Google Dataflow into a SQL queryable table in Google BigQuery with one row for each metric. The deviceId is an important identifier here. When using a more central technology service like BigQuery for a decentral data mesh ownership, it is important to clearly define boundaries within BigQuery. In this case, each data product becomes a different dataset within BigQuery enabling the teams to get specific access rights to only change and populate their data product. In data mesh, this kind of data product is called a source-aligned data product, because it is closely linked to the operational source system and exposes its data to the mesh. For showing this data in a graph, the team responsible for the dashboard in Google Data Studio can read directly from the output port of this data product.
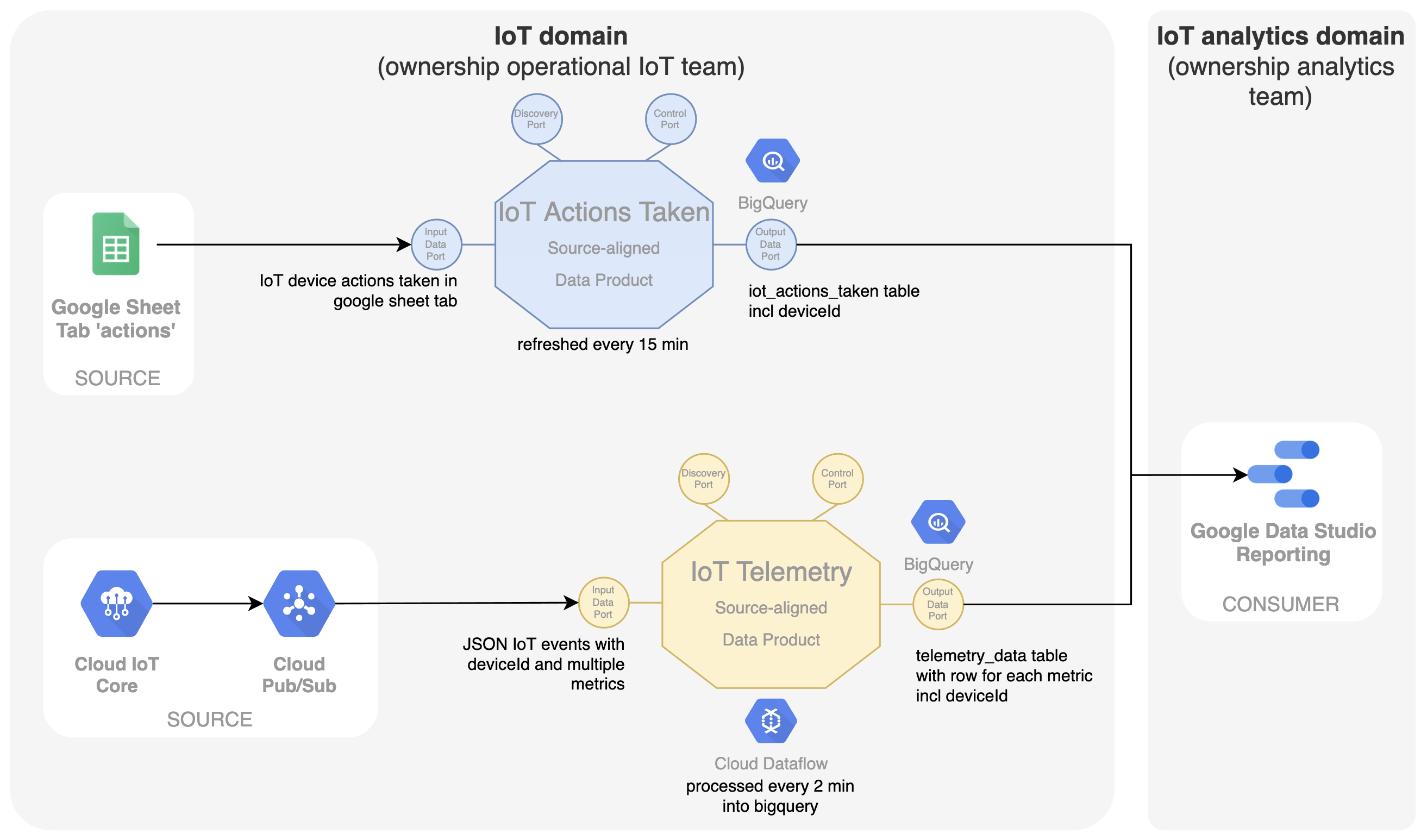
Next to the core telemetry data, additional data is gathered in simple Google sheets. A first sheet collects the actions taken as some kind of logbook. In the dashboard, these actions are plotted on the graphs showing the evolution of telemetry data. This shows the possible effect of the action. The IoT team working in the IoT domain is again owning this operational Google sheet and is thus responsible to expose the data as source-aligned data product called 'IoT Actions Taken'. Here, the Google sheet data on Google Drive is transformed into a queryable SQL table in BigQuery using a simple scheduled query into a separate table within the dataset of this data product.
The above schema shows that the analytics team directly consumes the output ports of both data products. This is often not an optimal solution. For the dashboard, a dataset combining all data optimized for consumption in that specific dashboard is preferred. A consumer-aligned data product 'Iot Analytics' is introduced for this (shown below). Data from both 'IoT Telemetry' and 'IoT Actions Taken' data products are input ports to this new data product. Based on the 'deviceId', the data is combined into a queryable and optimized SQL view in BigQuery. The ownership of this data product is also better aligned with the consumption use case, i.e. the dashboard in Google Data Studio. The analytics team is owner of the data product. This enables more speed and autonomy to change the dashboard and underlying optimized data structure within one team, resulting in more business agility.
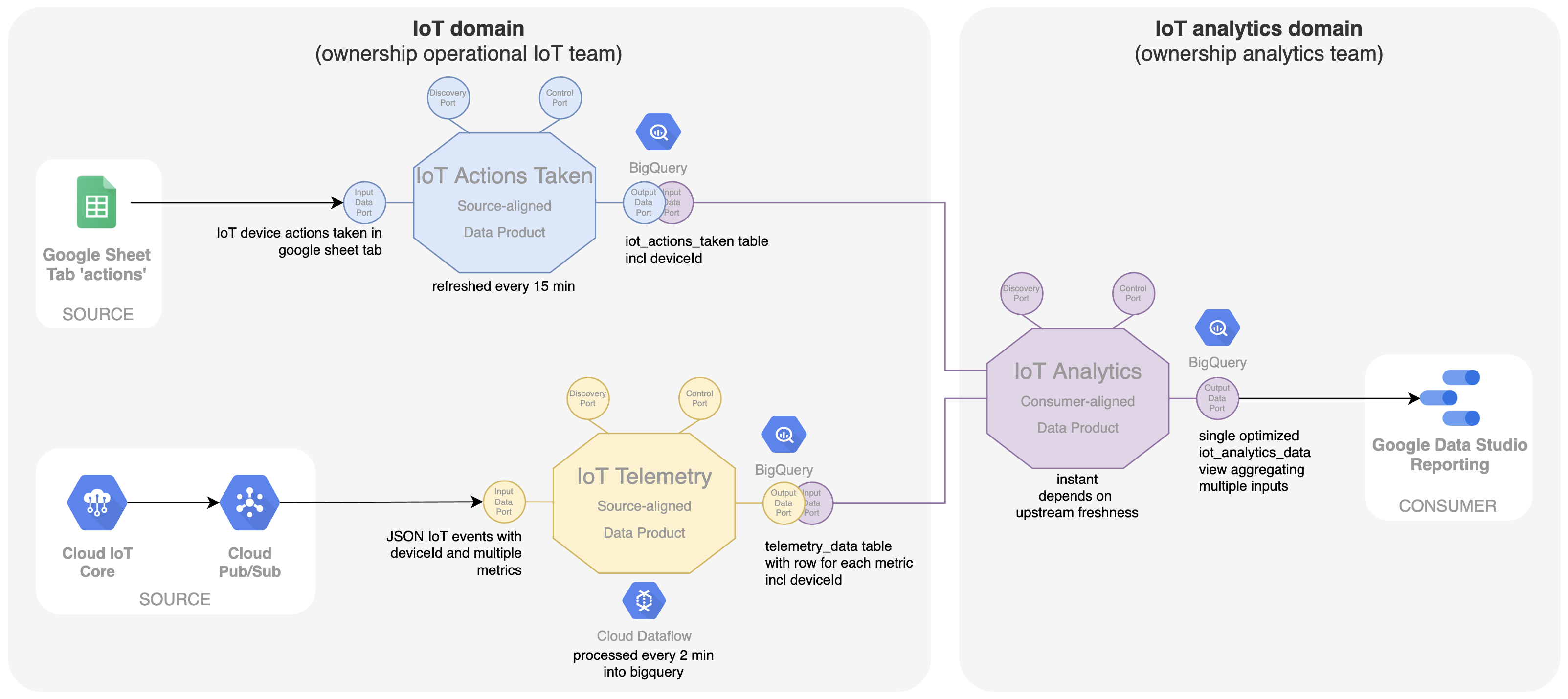
Similarly, additional metadata about the location of the device is kept in a Google sheet by end-users (e.g. the number of persons present in a room, external co2 level, etc). This data is also exposed by the IoT team as a separate source-aligned data product called 'IoT Metadata' and aggregated into the 'IoT Analytics' data product by the analytics team.
There is also a specific requirement which implies that a single device with a deviceId is not exclusive for one customer. Over time, a device can be relocated to another customer. This means that the solution should support multi-tenancy in which data (telemetry, actions, metadata) is kept separate, so that customers or tenants can only see the data that was relevant at the time the device was located with them. For this, a tenantId was introduced as additional data property in all operational systems and all source-aligned data products. Note that for the 'IoT Telemetry' data product this tenantId is not included in the data coming from the devices. We can only get this tenantId from the 'IoT Metadata' data product at the moment a telemetry data point comes in. The 'IoT Metadata' data product gets an additional output port facilitating the mapping of deviceId to tenantId. This port is then an additional input port for the 'IoT Telemetry' data product to make sure that the tenantId is included with every metric provided in the output port. The analytics team can then adapt its 'IoT analytics' data product and dashboards to take this multi-tenancy into account.
The end-result including the metadata data product and multi-tenancy support is shown below.
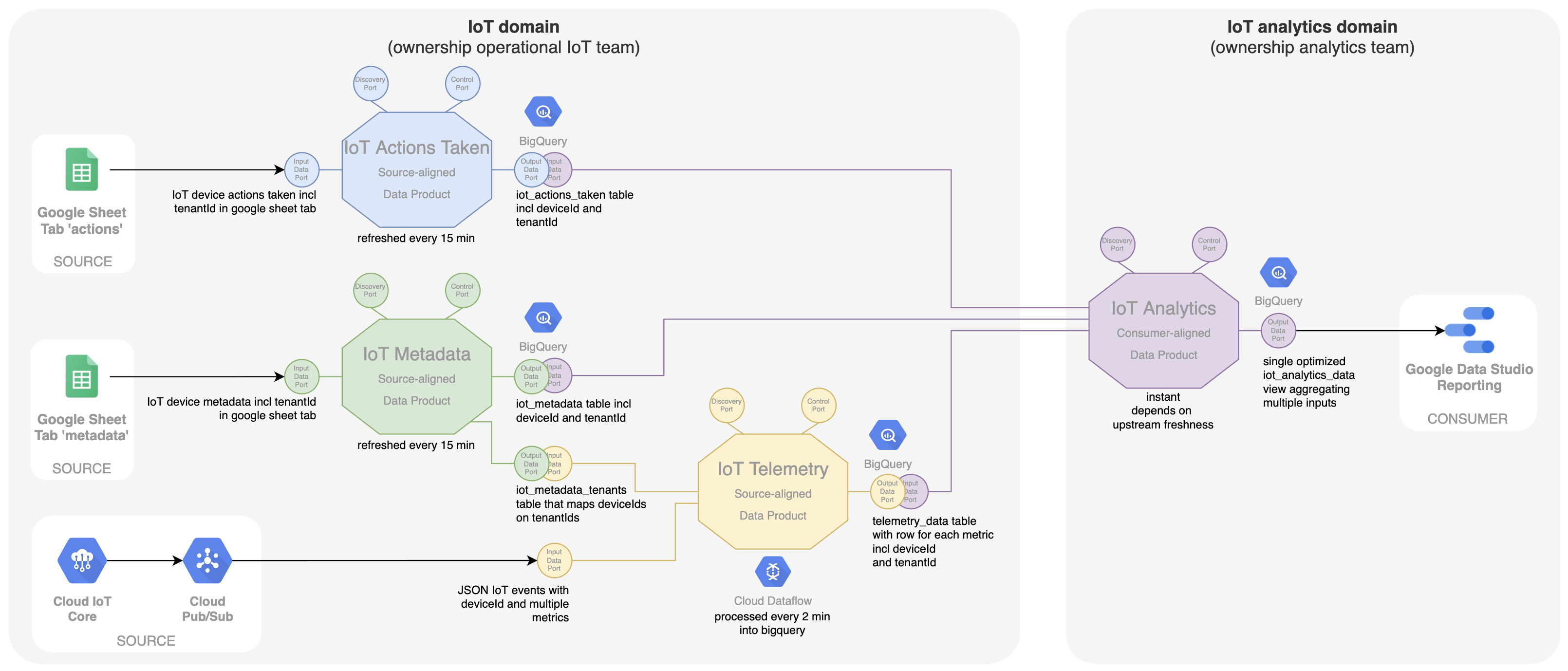
Separate data products are created to expose each operational system or dataset. Why not just one data product for each domain with multiple input ports? Well, there are a number of reasons, trade-offs or design best practices that advise not to do this:
- data products should be functionally highly cohesive and all three operational systems are concerned with very different data sets (telemetry vs metadata vs actions logbook)
- separating them also provides a separate lifecycle with the option to evolve at their own pace, thus offering more flexibility
- with multiple data products, it becomes possible to reason about moving the ownership of certain data products to other domains or domain teams when additional insights point in that direction. There's an example below concerning customer metadata.
- the data mesh concept also explicitly states that it is not the intention to only have one data product for each domain, but to design a logical decomposition into multiple data products that a domain can offer. A domain can be rather big and complex and the different 'main concepts' are typical candidates to align data products with (cf. design pattern of 'aggregates' in domain driven design)
- for data products that are more source-aligned, it's advised to align with concepts in the source system, rather than tuning it too much towards the consumption and aggregated views a dashboard needs
- the above separation also allows scenarios in which only the 'IoT Telemetry' data product is used and e.g. 'IoT Actions Taken' is irrelevant. When this is combined in one coarse-grained data product, the scenario also receives the actions data in which it is not interested. With two separate data products, these dependencies become more explicit. A change to the 'IoT Actions Taken' data product then does not impact scenarios that only use the 'IoT Telemetry' data.
As a side note, in the 'IoT metadata' data product there are actually two types of metadata. There is metadata about where the IoT device is located (room, floor level, building, ...). But there is also metadata that is more concerned with the customer or tenant itself. Probably there is some kind of CRM system which is the true master of the customer data and from which the customerId should equal the tenantId in our data mesh. A better domain ownership and more optimal way of working would be to ask the team responsible for the CRM system to also provide a source-aligned 'Customers' data product with a customerId and metadata about the customer. Then this no longer needs to be entered in the Google sheet of IoT metadata. Additionally, the analytics team would not only get more customer data, but also more accurate data as it comes directly from the source.
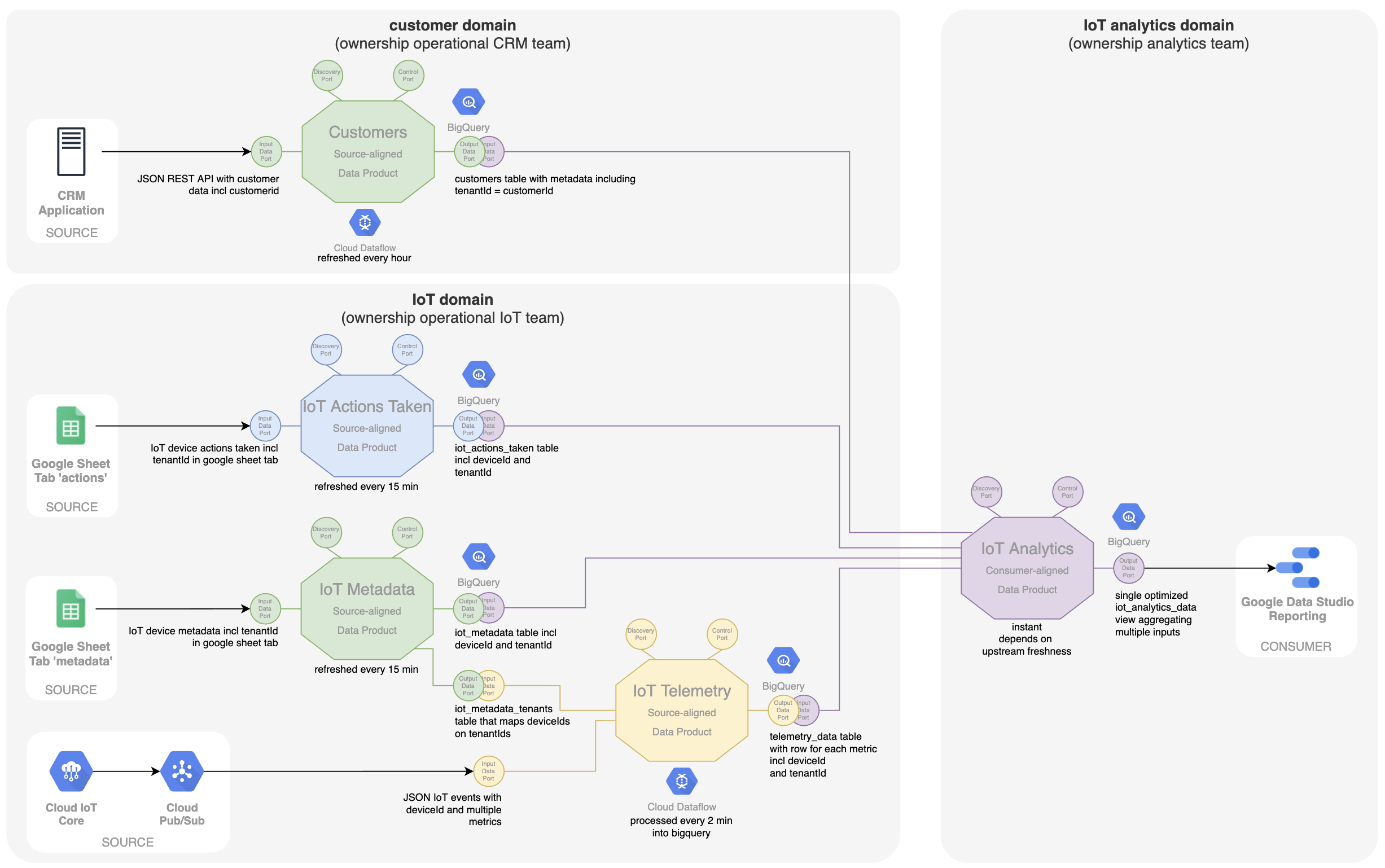
This process illustrates that thinking in terms of data products as building blocks is a helpful design paradigm for designing and evolving a data platform. The paradigm makes it clear where the ownership of certain data needs to be put. This ownership implies that this owning team is responsible to maintain and evolve the data product, depending on the requirements of the consumers and the evolution of the data in the source operational system.
A poor man's self-serve data mesh platform
In this blog post, we only lightly touched two data mesh principles: domain-oriented ownership and data as a product. Domain-oriented ownership was explored by explicitly defining domain boundaries and assigning each data product to a domain team. Data as a product was explored by thinking in terms of 'data products', not only as building blocks, but also about how to maximize usability of data towards consumption.
We did not touch on the principles of self-serve data platform and federated computation governance in the example use case. When implementing your data mesh journey, there is a whole spectrum to consider from no self-service and automation capabilities at all, all the way towards a full-fledged automated self-serve data platform. Let's illustrate this a bit further.
In the example above, we allowed ownership to be given to a domain team on a technical level. We aligned one data product with one source code repository which then can be owned by one team. So all transformation code, infrastructure-as-code, etc is part of one code repository. For infrastructure-as-code, we used scripts with the gcloud command line interface. These scripts are also embedded in the same code repository and enable to develop, build, setup, deploy, and change the data product.
On the infrastructure level, we used the self-serve infrastructure platform of Google Cloud. The self-service is purely focused on infrastructure. This provides too much flexibility to development teams without uniform guidance and/or control. However, this is important to make sure the resulting data mesh is a coherent and consistent set of data products.
In that sense, the end-result here could be called a 'poor man's self-serve data mesh platform' on that spectrum of self-service and automation. It does not necessarily mean that we're not reaching our goals. This might be enough to have the advantages of a data mesh design paradigm, and still end up with a good architecture, clear ownership, and business agility to make changes.
Taking it to the next level
A next step on the spectrum towards a full-fledged self-serve data platform, would be to raise the abstraction level at which a data product developer interacts with the self-service platform. Then you consider a 'data product' as the smallest deployable architectural unit around which automation and tooling is developed to enable self-service. We can abstract away the pure infrastructure complexity by enabling declarative specification and full automation of things like provisioning of storage and API endpoints. The goal is to make it very easy to share data as a product so that there is no reason not to share your data as a team.
Another step is to also consider the data mesh network as a whole and introduce capabilities at the mesh level like
- data product discovery through a data catalog,
- automating governance policies to increase the consistency and quality of the data and data products, i.e. federated computation governance,
- collecting data quality and usage metrics as additional metadata in the data catalog,
- ...
The goal is to make it very easy to find, select, consume and re-use data in a great data platform user experience.
How far you take this data mesh journey with respect to self-service data platform tooling and automation depends on the complexity of the use cases, the scale of the organization, the technical skills of data product developers, the available funding, the vision for the future, and much more. In short: It depends, and is a topic for future blog posts. 😉
Are you also working on your data mesh journey and want to share ideas? Or are you thinking about doing it and need advice? Struggling with your data platform architecture? Do not hesitate to get into contact with our great team!











