


Data Product Analysis: How Do I Start?
In the world of data mesh, data products are key. But what exactly is a data product and how do you approach the functional analysis of such a data product? You will discover it in this blog post.
Data Product?
The basic idea of a data mesh consists of 2 parts:
- Increasing the accessibility, availability and usability of data for business users.
- Reducing dependencies between data teams.
We base our approach on the principles of domain-oriented ownership, federated computational governance, self-service data platforms and product thinking. Particularly the latter is crucial in understanding and developing a data product. We aim to consider and shape data as a reusable product, enabling it to be utilised in various ways, thus maximising its value.
A data product is an autonomous, read-optimised, standardised data unit containing at least one dataset (Domain Dataset), created for satisfying user needs
— Majchrzak Jacek, Author at Data Mesh in Action



It is a logical unit that encompasses all components required to process and store domain-specific data for various use cases, such as data analytics, and makes it accessible to other teams through 'output ports'. A data product also has its own independent lifecycle and management structures. In essence, you can compare a data product to a microservice, but designed for analytical data.
Data products connect to sources through input ports, such as operational systems, data platforms, or other data products, and perform specific operations on the data, such as transformations, calculations, data anonymisation, and more.
Developing a data product involves addressing various aspects, including defining input and output ports, data cleaning, transformations, field mapping, GDPR compliance, and so on. Therefore, a thorough analysis is crucial.
But, how do you start such a data product analysis?
Step-by-step Guide for Data Product Analysis
A structured analysis approach ensures the best results. For data products, we rely on the Data Product Canvas, which we pair with a useful checklist.
The canvas is a visual representation that simplifies the display of the various critical components of your data product analysis. The checklist ensures that you don't overlook anything.
Data Product Canvas
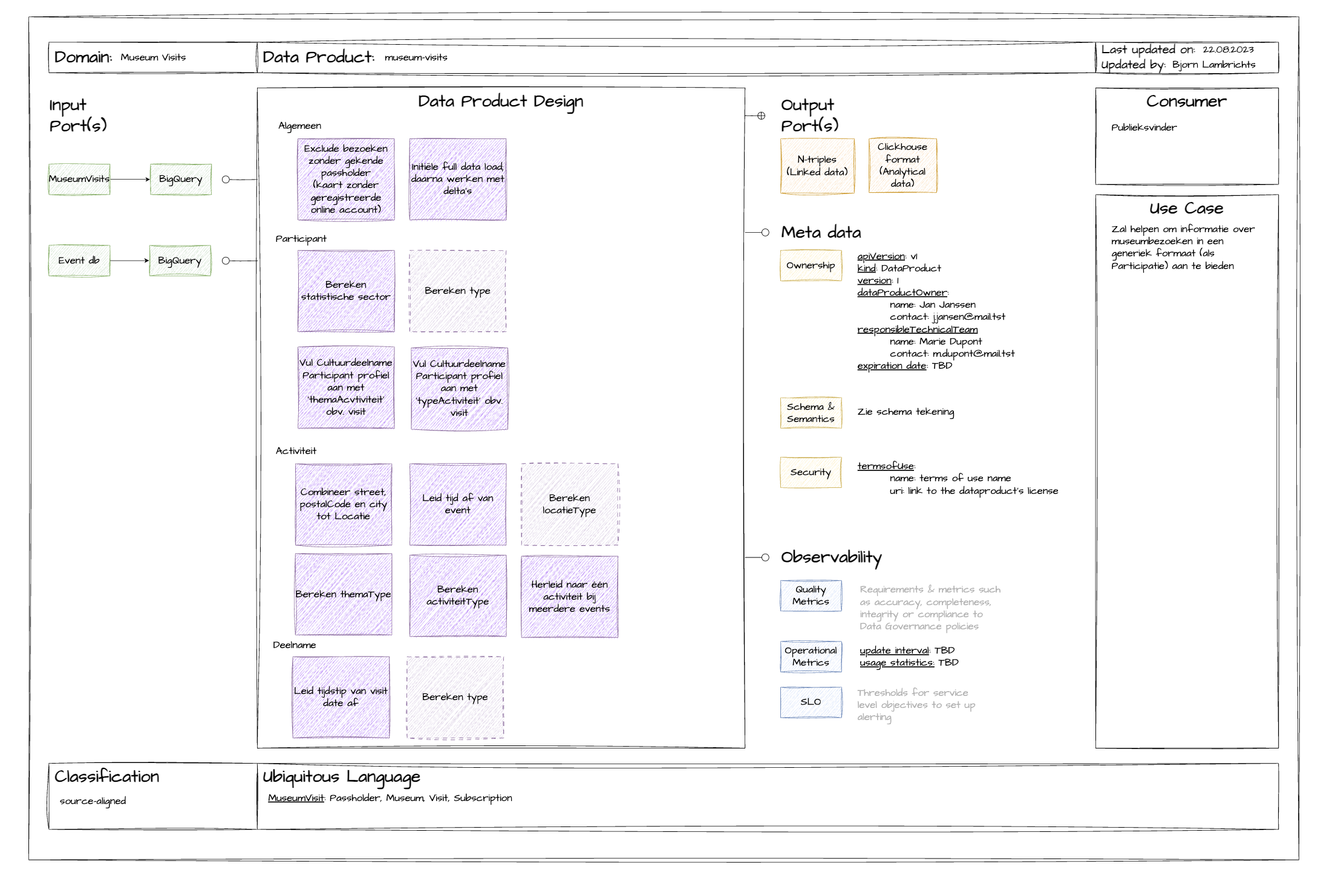
With the Data Product Canvas, we ensure a consistent process for designing a data product within an organisation. The canvas succinctly outlines the aspects you need to consider during your analysis.
Using this canvas, you can engage various stakeholders of the data product. This collaborative effort leads to the desired result.
Based on our experience with this canvas, we recommend filling it out in a specific sequence. It's best to start with specifying the data product. This way, you immediately capture all descriptive data, ensure that all stakeholders are well-informed, and clarify the data product's purpose. Next, move on to the output ports since the data product's stakeholders often have a good understanding of the data they require. You can compare them with end-users of an application who benefit from a good user experience. Afterwards, address the input ports. Based on feedback from data consumers, you will identify the input sources capable of providing the necessary data. Finally, conclude with the data product's design. In this phase, input and output converge, and you aim to come up with a logical approach to transform input into the desired output.
Checklist
1. Data Product Specification
Make sure to collect all the descriptive data for your data product. This includes:
- Domain name
- Data product name
- Ownership: who manages the data product: The technical team's contact information, The technical team's contact information, The data product's expiration date)
- Security: Data product security is crucial: it determines how and by whom the data product can be used. Specify the license or 'terms of use' associated with the data product.
- Update frequency: The frequency determines how often the data product is updated. It's a good idea to also indicate how the updates are performed (e.g., full load, incremental, etc.).
- Data Consumers: A data product's data consumers are applications or other data products that will use your data product's output.
- Use cases: Use cases describe your data product's purpose. They provide more information about the data product's needs and rationale.
2. Terminology
In many companies and projects, confusion often arises regarding the meaning of certain concepts, terms, or words. Ubiquitous language, a Domain Driven Design principle, seeks to provide a solution by aiming for a vocabulary that is shared and clearly understood by all stakeholders.
To avoid speech confusion and interpretation differences when developing and analysing a data product, it's crucial to pay attention to ubiquitous language. Therefore, be sure to include definitions of terms that are relevant within the context of the data product. References to other glossaries, wikis, etc., are also welcome.
3. Output Ports
Output ports determine the format and protocol in which data is made available to your data consumers. Discuss with your data consumers (and other stakeholders) the format in which they prefer to consume data. Examples of output port types include analytical data, blob stores, Linked Data, etc.
4. Input Ports
Input ports specify the format and method by which source data can be read. By reaching out to the owners of your source systems (or source data products), you can discover the available options.
Be sure to mention the type of input port (e.g., API, database, file, etc.), and also note which tables of the source system the required data can be extracted from.
It's also very useful to include a visual representation of the source system's domain at this stage.
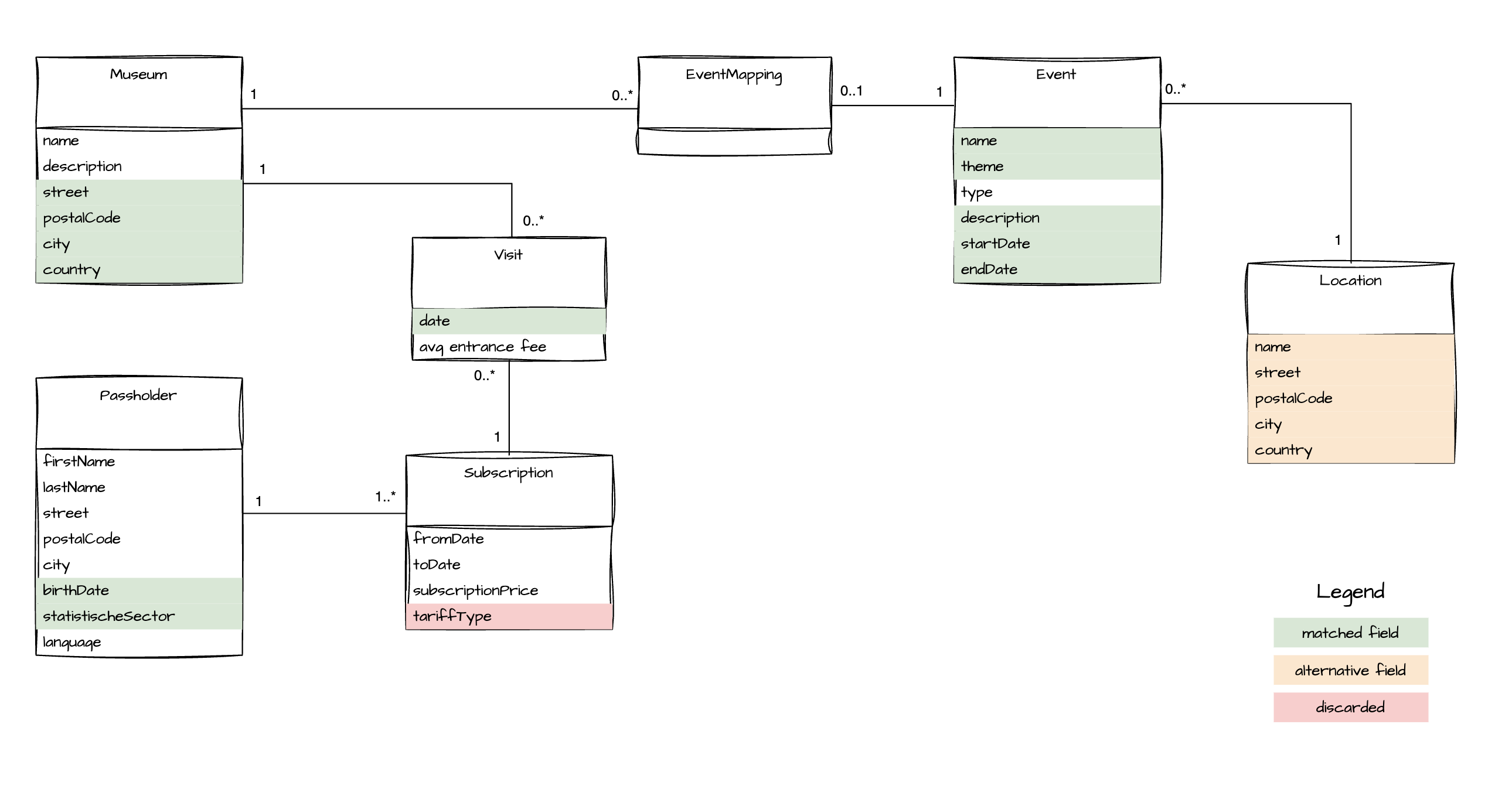
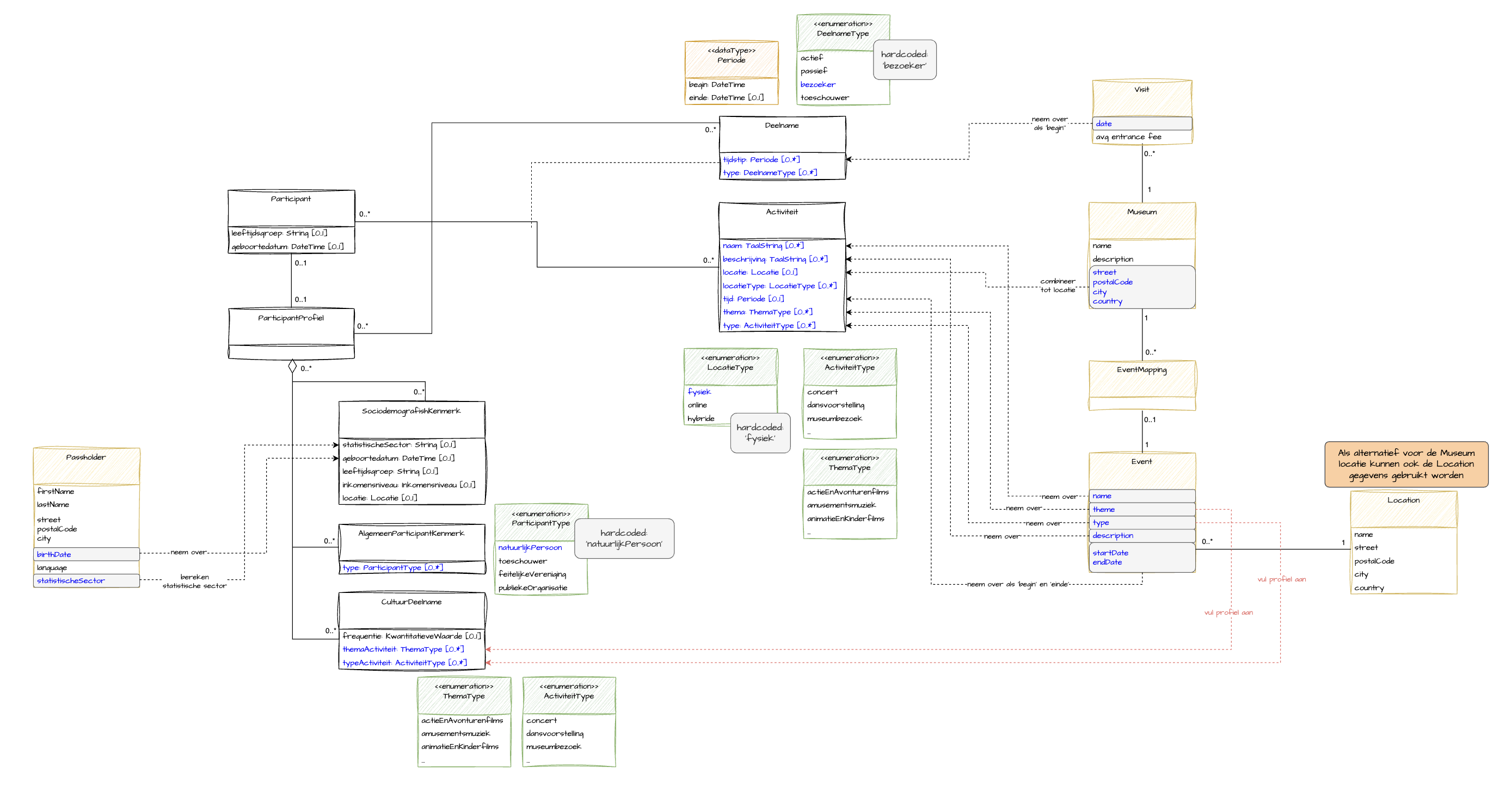
5. Data Product Design
This is the final and perhaps the most critical step in a data product's analysis. In this step, you will think about the logic of transformations within the data product. Consider:
- Identification of desired input data/fields
- Identification of desired output data/fields
- Constraints on data input (e.g. not all information is available in all cases)
- Data cleaning
- Data transformations
- Input field mapping
- Output field mapping
- Data enrichment
- Data anonymisation (e.g., in compliance with GDPR regulations)
- Data calculations
In the practical example below, we address several of the above topics. It illustrates how source fields are mapped and how to handle them effectively. Additionally, certain fields are calculated based on input data (e.g., location).
In Conclusion
Analysing data products involves many aspects. However, with a well-structured approach, a visual framework, and a simple checklist, you can complete this task with ease.
💡 Would you like to learn more about data mesh or the ACA methodology? Then, please contact us by filling in the form.





